6. Data warehouse optimization
6.1 Introducción
Un sistema de datawarehouse dentro de una organización no solo necesita proveer un ambiente de consultas de buena y ágil respuesta, sino ser rápido y preciso para satisfacer las necesidades de su comunidad de usuarios.
Para ello no solamente se deben examinar aspectos de creación de una base de datos física eficiente, sino también examinar como mejorar el proceso de desarrollo y el modelo.
6.2 Mejorando el proceso de desarrollo
El proceso de desarrollo incluye análisis y diseño, así como la codificación de la carga de datos y la publicación de aplicaciones.
6.2.1 Optimizing Design and Analysis
Resta poco que mencionar para crear un buen análisis y diseño de un datawarehouse. Quizás los más destacable desde el punto de vista de optimización es que siempre es mejor hacer los cambios en el papel, que en un sistema en producción lo cual involucra cambiar también schemas y procesos. De manera que un esfuerzo adicional para crear el modelo correcto tiene sus frutos posteriormente ya que los cambios necesarios serán mínimos.
6.2.2 Optimizing Application Development
6.2.2.1 Selecting an ETL tool
Una buena herramienta ETL provee un ambiente de desarrollo especialmente diseñado para realizar los tipos de tareas necesarias para cargar y entregar data warehouses. El uso de tales herramientas puede reducir dramáticamente el esfuerzo desarrollo de desarrollo sobre métodos tradicionales de codificación usando lenguajes como COBOL, C, Java, o SQL. Se tienen reducciones de esfuerzo en el tiempo de desarrollo del 60% y de hasta 80% para aquellos que tienen experiencia con la herramienta.
Algunos puntos a considerar en la evaluación:
- Data access. Dónde se encuentran los datos y los dbms a utilizar ? La herramienta puede conectarse con esas fuentes ? Cómo se administran las conexiones? Cómo se transmiten los datos por la red ?
- Throughput. La herramienta soporta "memory caching" para código y llaves ? Se pueden ejecutar transformaciones asíncronas en distintos procesadores ?
- Extensibility. Existen las transformaciones requeridas ? se puede implementar alguna personalizada ?
- Real-time data acquisition. Se requiere recolección de datos en tiempo real ? la herramienta lo soporta ? necesita alguna interface para software de mensajes ?
- Meta data. Se pueden agregar metadatos al proceso ?
- The tool’s development environment. Los desarrolladores se adaptan al GUI ? cómo se integra con otros procesos o módulos ? maneja control de acceso, versiones ? se puede llevar control de QA (debug, test)?
- Your environment. qué volúmenes de datos se van a manejar ? se permite el streamming de datos ? la herramienta tiene algun requerimiento especial ? puede coexistir en el mismo servidor del data warehouse ?
- Proof of concept. El vendedor está dispuesto a realizar una prueba de concepto ?
- Vendor. evaluar al proveedor mismo.
6.2.2.2 Optimizing the Database
Data Clustering
Involucra colocar tuplas relacionadas de distintas tablas dentro del mismo bloque de disco, de esta manera los joins se hacen rápidamente.
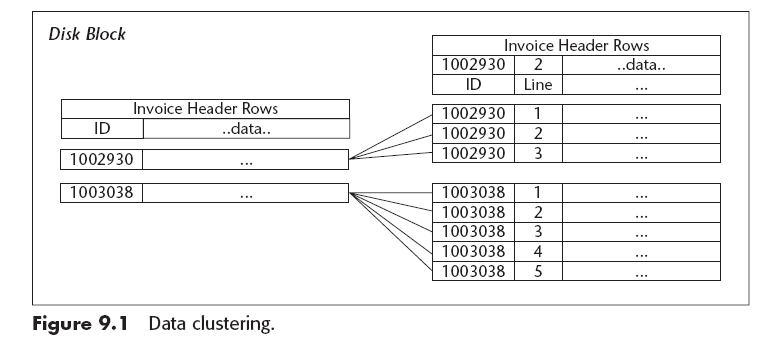 |
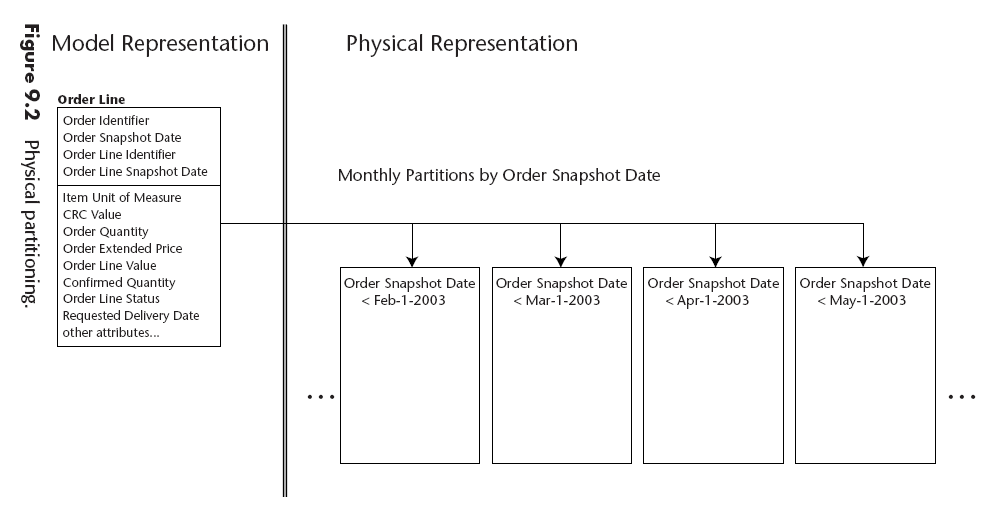
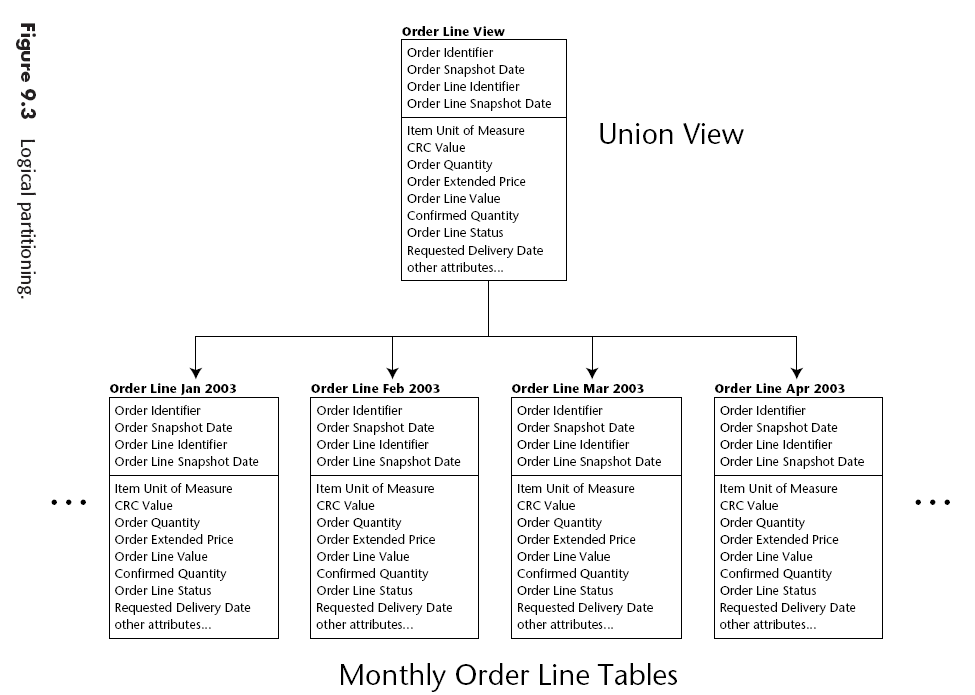
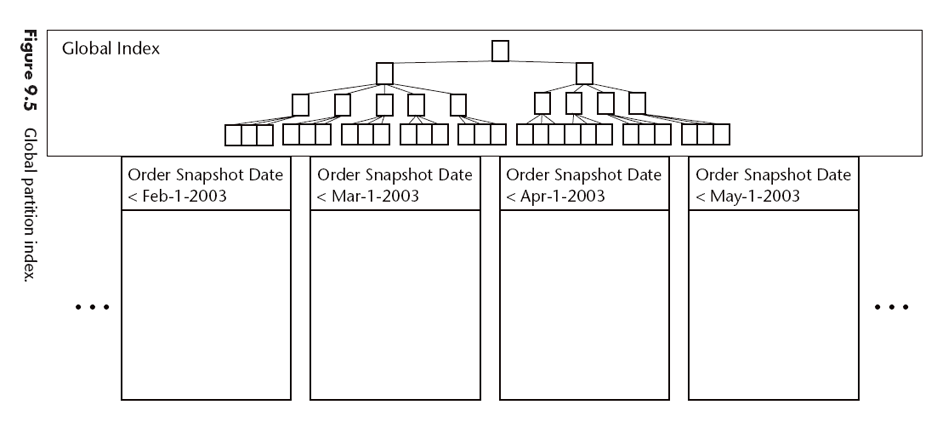
Table Partitioning
Conocido también como "horizontal partitioning", divide una tabla en muchas subtablas con las mismas columnas. La división puede hacerse por algun criterio ej. Años, Ciudades, etc.
Las particiones pueden ser físicas o lógicas.
Existen 2 razones básicas para particionar tablas:
- mejorar el manejo.
- mejorar el tiempo de respuesta a través de queries paralelos a grances conjuntos de datos.
 |
 |
 |
 |
Enforcing Referential Integrity
Sin lugar a dudas mantener la integridad referencias es útil y necesario para manejar un datawarehouse. El problema ocurre cuando se cargan grandes cantidades de datos, ya que checar las llaves foráneas puede alentar el proceso; por ello se puede deshabilitar el uso de llaves foráneas temporalmente o bien revisar la integridad referencial previamente, desde la herramienta ETL y no en la base de datos.
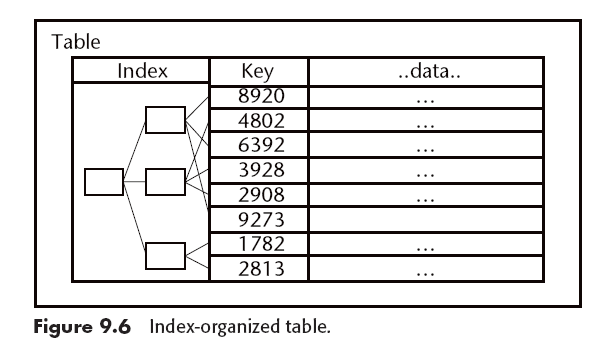
Index-Organized Tables
Si se puede utilizar un índice dentro del mismo espacio de los datos esto es mucho mejor.
 |
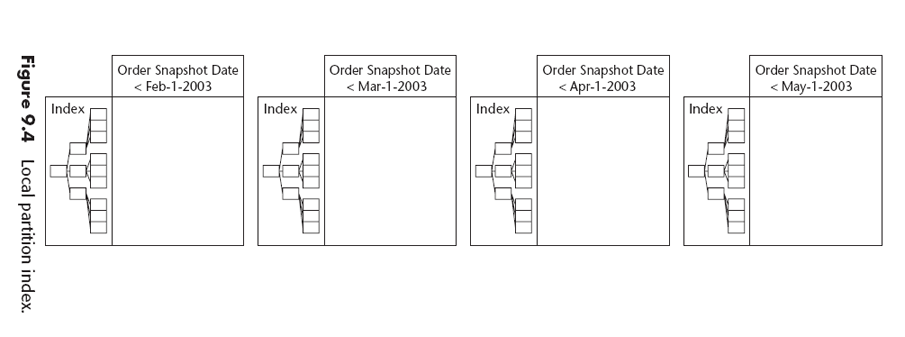
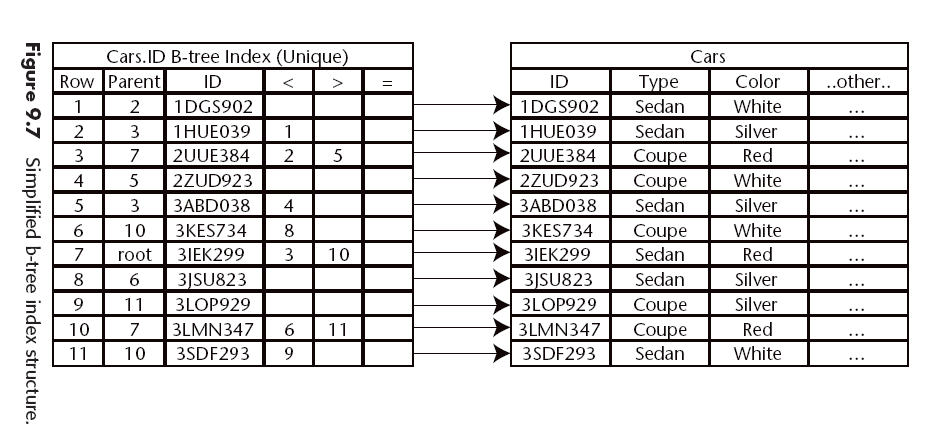
Indexing Techniques
- B-Tree Indexes
 |
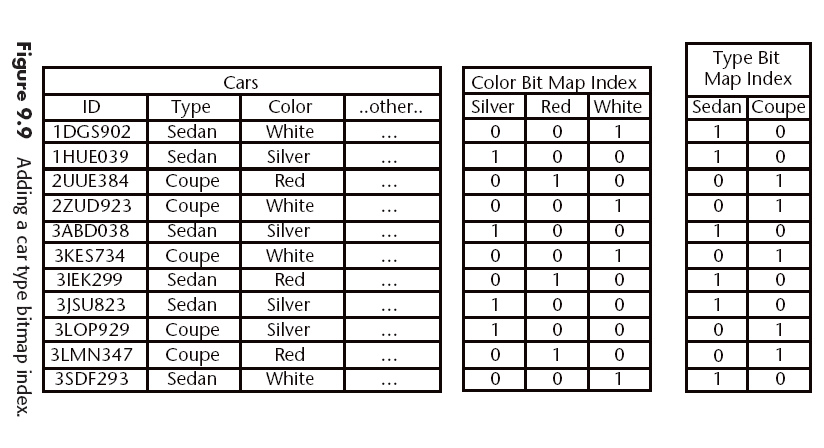
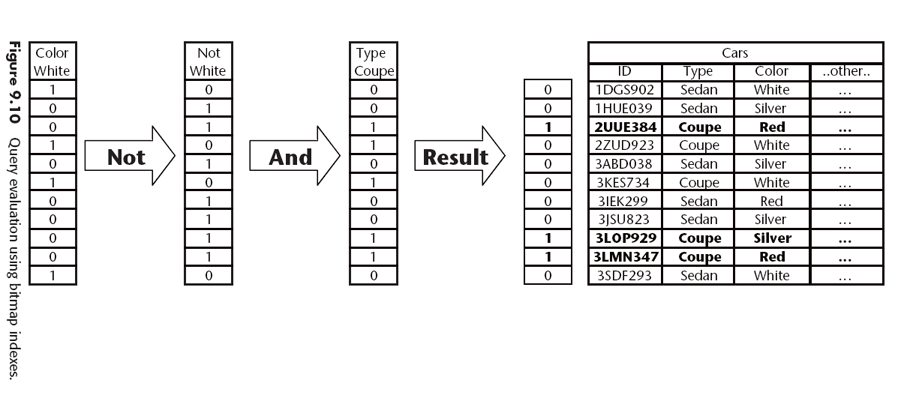
- Bitmap Indexes
Los más adecuados para modelos multidimensionales porque pueden combinarse.
 |
 |
6.3 Mejorando el modelo
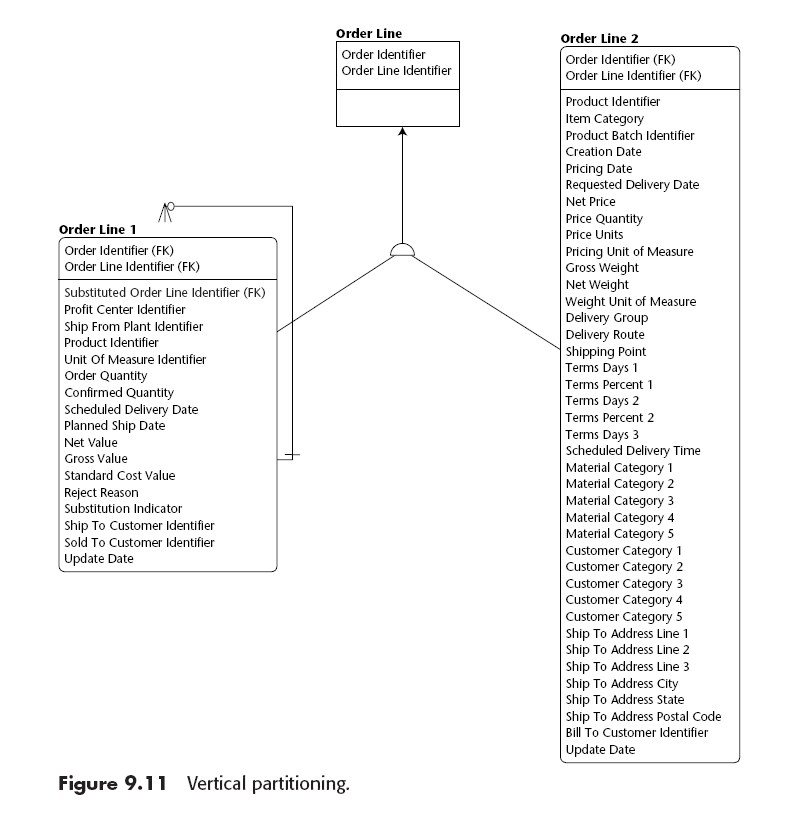
Vertical Partitioning
Razones:
- Performance
- Change/Update History
- Large text
 |
Denormalization
Aumentar la velocidad de joins juntando anticipadamente varias tablas.
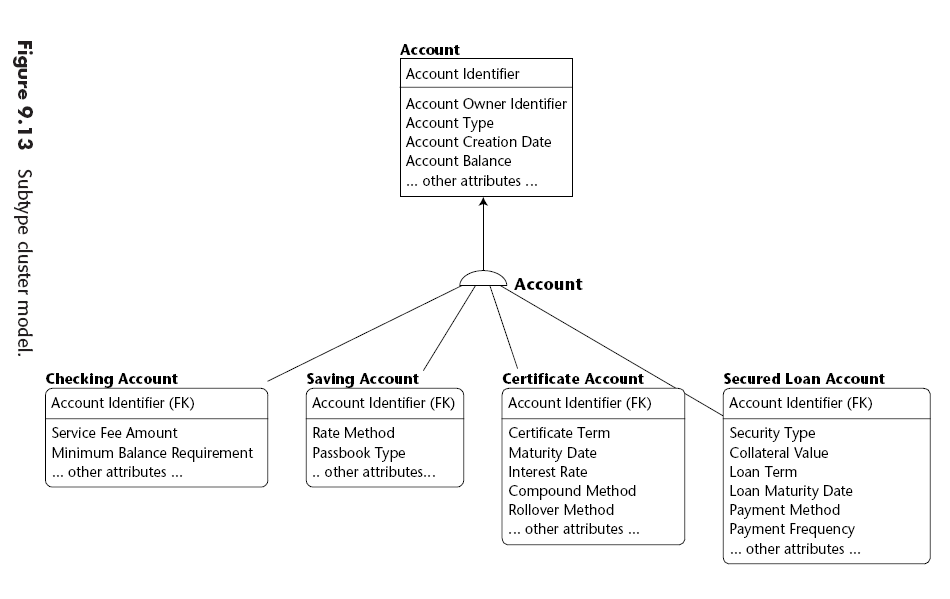
Subtype Clusters
Existen 2 alternativas para la implementación física dentro de un datawarehouse:
- La primera es implementar una sola tabla con todos los atributos y
- la otra es implementar solamente las tablas de los subtipos donde cada tabla contiene también los atributos del supertipo.
 |