Un XLink permite establecer una relación entre dos o más recursos en la Web, sin que necesariamente estos recursos sepan que están enlazados. Otra cosa es cómo se nota eso al navegar por páginas XML.
Datos semiestructurados:
Los documentos pueden ser validados contra una especificación, la cual puede ser definida con:
Los documentos pueden ser interrogados a través de lenguajes de consulta, actualmente existen estándares para ello:
Tag : etiqueta para una sección de datos
Element :sección de datos que comienza con un <tagname > y termina con su correspondiente </tagname >
Attribute:
adjetivo que califica alguna caraterística de un elemente y que se representa
a través de una combinación de nombre="valor"
<account acct-type = checking >
<account-number> A-102 </account-number>
<branch-name> Perryridge </branch-name>
<balance> 400 </balance>
</account>
El texto contenido en un elemente puede estar encerrado en una sección CDATA
para permitir caracteres especiales
<![CDATA[<account> </account>]]>
Namespaces
De manera que este nombre único está compuesto de un prefix y un nombre, la idea es definir el prefix con un URI (Universal Resource Identifiers) asociado de manera que así se garantiza que no existan repeticiones. De manera que cada tag se nombraría con el URI seguido del nombre del tag; ya en la práctica, el prefix se declara al emplear por primera vez el tag a renombrar de manera que durante todo el documento el nuevo prefix ya se puede emplear para diferenciar los distintos tags:
<{http://www.w3.org/TR/xhtml1}head>
|
<... xmlns:foo="http://www.w3.org/TR/xhtml1"> ... <foo:head>...</foo:head> ... </...> |
Ej.
<bank Xmlns:FB=http://www.FirstBank.com>
<FB:branch>
<FB:branchname>Downtown</FB:branchname>
<FB:branchcity> Brooklyn </FB:branchcity>
</FB:branch>
</bank>
Los esquemas son las especificaciones que definen qué información puede estructurar un documento XML así como los tipos de datos posibles para los distintos elemento y atributos
Los documentos XML no necesariamente tienen asociado un esquema, sin embargo son importantes para el intercambio de infomación.
Como se mencionó anteriormente, existen 2 mecanismos para definir estos esquemas: DTDs y XML Schema.
DTD syntax
Sintáxis de Elementos
<!ELEMENT element (subelements-specification) >
<!ATTLIST element (attributes) >
donde los Subelements pueden ser
especificados como
nombres de elementos
#PCDATA (parsed character data), i.e., character strings
EMPTY (no subelements) o ANY (lo que sea puede ser un subelement)
Los Subelements también contienen expresiones regulares para indicar secuencia
y cardinalidad
<!ELEMENT bank ( ( account | customer | depositor)+)>
Notación:
| - alternatives
+ - 1 or more occurrences
* - 0 or more occurrences
<!DOCTYPE bank [
<!ELEMENT bank ( ( account | customer | depositor)+)>
<!ELEMENT account (account-number branch-name balance)>
<! ELEMENT customer(customer-name customer-street customer-city)>
<! ELEMENT depositor (customer-name account-number)>
<! ELEMENT account-number (#PCDATA)>
<! ELEMENT branch-name (#PCDATA)>
<! ELEMENT balance(#PCDATA)>
<! ELEMENT customer-name(#PCDATA)>
<! ELEMENT customer-street(#PCDATA)>
<! ELEMENT customer-city(#PCDATA)>
]>
La especificación de Attribute:
Name
Tipo
CDATA
ID (identifier) o IDREF (ID reference) o IDREFS (multiple IDREFs)
Whether
mandatory (#REQUIRED)
or neither (#IMPLIED)
<!ATTLIST account acct-type CDATA checking>
<!ATTLIST customer
customer-id ID # REQUIRED
accounts IDREFS # REQUIRED >
IDs y IDREFs
| <!DOCTYPE bank-2[ <!ELEMENT account (branch, balance)> <!ATTLIST account account-number ID # REQUIRED owners IDREFS # REQUIRED> <!ELEMENT customer(customer-name, customer-street, customer-city)> <!ATTLIST customer customer-id ID # REQUIRED accounts IDREFS # REQUIRED> declarations for branch, balance, customer-name, customer-street and customer-city]> |
<bank-2> <account account-number=A-401 owners=C100 C102> <branch-name> Downtown </branch-name> <balance> 500 </balance> </account> <customer customer-id=C100 accounts=A-401> <customer-name>Joe </customer-name> <customer-street> Monroe </customer-street> <customer-city> Madison</customer-city> </customer> <customer customer-id=C102 accounts=A-401 A-402> <customer-name> Mary </customer-name> <customer-street> Erin </customer-street> <customer-city> Newark </customer-city> </customer> </bank-2>
|
Definición del dtd asociado a un documento XML
<?xml version="1.0" standalone="no"?>
<!DOCTYPE BOOK SYSTEM "http://www.library.org/book.dtd">
<BOOK>
......
</BOOK>
| <xsd:schema xmlns:xsd=http://www.w3.org/2001/XMLSchema> <xsd:element name=bank type=BankType/> <xsd:element name=account> <xsd:complexType> <xsd:sequence> <xsd:element name=account-number type=xsd:string/> <xsd:element name=branch-name type=xsd:string/> <xsd:element name=balance type=xsd:decimal/> </xsd:squence> </xsd:complexType> </xsd:element> .. definiciones de customer y depositor . <xsd:complexType name=BankType><xsd:squence> <xsd:element ref=account minOccurs=0 maxOccurs=unbounded/> <xsd:element ref=customer minOccurs=0 maxOccurs=unbounded/> <xsd:element ref=depositor minOccurs=0 maxOccurs=unbounded/> </xsd:sequence> </xsd:complexType> </xsd:schema>
|
De manera general un XML Schema consiste de 2 partes:
Más ejemplos, creación de business cards.
documento john_doe.xml:
<card xmlns="http://businesscard.org"> <name>John Doe</name> <title>CEO, Widget Inc.</title> <email>john.doe@widget.com</email> <phone>(202) 456-1414</phone> <logo url="widget.gif"/> </card> |
Para describir la sintáxis de este lenguaje, se desarrolla el schema business_card.xsd:
<schema xmlns="http://www.w3.org/2001/XMLSchema"
xmlns:b="http://businesscard.org"
targetNamespace="http://businesscard.org">
<element name="card" type="b:card_type"/>
<element name="name" type="string"/>
<element name="title" type="string"/>
<element name="email" type="string"/>
<element name="phone" type="string"/>
<element name="logo" type="b:logo_type"/>
<complexType name="card_type">
<sequence>
<element ref="b:name"/>
<element ref="b:title"/>
<element ref="b:email"/>
<element ref="b:phone" minOccurs="0"/>
<element ref="b:logo" minOccurs="0"/>
</sequence>
</complexType>
<complexType name="logo_type">
<attribute name="url" type="anyURI"/>
</complexType>
</schema> |
Se puede observar que el schema es un documento XML asociado al namespace http://www.w3.org/2001/XMLSchema.
Por otro lado, todo documento que desee hacer referencia a este schema deberá indicarlo de la siguiente manera:
<card xmlns="http://businesscard.org"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://businesscard.org
business_card.xsd">
...
</card> |
Los componentes de un schema son:
(global) element declaration que asocia el nombre de un elemento con un tipo
complex type definition define requerimientos para atributos y subelementos
attribute declarations: describen los atributos que podrían y/o deben aparecer
element references: describen cuales subelementos podrían y/o deberían aparece
a simple type definition definen un conjunto de strings a ser usadas como valores de atributos datos de caracteres
Local definitions
En lugar de escribir todas las declaraciones de elementos y definiciones de tipo de manera global, pueden ser insertados localmente (inlined):
Ejemplo:
<element name="card" type="b:card_type"/>
<element name="name" type="string"/>
<complexType name="card_type">
<sequence>
<element ref="b:name"/>
<element ref="b:title"/>
<element ref="b:email" maxOccurs="unbounded"/>
<element ref="b:phone" minOccurs="0"/>
<element ref="b:background" minOccurs="0"/>
</sequence>
</complexType> |
representa lo mismo que:
<element name="card">
<complexType>
<sequence>
<element name="name" type="string"/>
<element ref="b:title"/>
<element ref="b:email" maxOccurs="unbounded"/>
<element ref="b:phone" minOccurs="0"/>
<element ref="b:background" minOccurs="0"/>
</sequence>
</complexType>
</element> |
Un lenguaje de esquemas desarrolado en cooperación por BRICS
y AT&T Labs Research.
DSD está diseñado para:
Ejemplo con DSD
<dsd xmlns="http://www.brics.dk/DSD/2.0"
xmlns:r="http://recipes.org"
root="r:collection">
<if><element name="r:collection"/>
<declare><contents>
<element name="r:description"/>
<repeat><element name="r:recipe"/></repeat>
</contents></declare>
</if>
<if><element name="r:description"/>
<rule ref="r:ANYCONTENT"/>
</if>
<if><element name="r:recipe"/>
<declare><contents>
<sequence>
<element name="r:title"/>
<repeat><element name="r:ingredient"/></repeat>
<element name="r:preparation"/>
<element name="r:nutrition"/>
</sequence>
<optional><element name="r:comment"/></optional>
</contents></declare>
</if>
<if><element name="r:ingredient"/>
<declare>
<required><attribute name="name"/></required>
<attribute name="amount">
<union>
<string value="*"/>
<stringtype ref="r:NUMBER"/>
</union>
</attribute>
<attribute name="unit"/>
</declare>
<if><not><attribute name="amount"/></not>
<require><not><attribute name="unit"/></not></require>
<declare><contents>
<repeat min="1"><element name="r:ingredient"/></repeat>
<element name="r:preparation"/>
</contents></declare>
</if>
</if>
<if><element name="r:preparation"/>
<declare><contents>
<repeat><element name="r:step"/></repeat>
</contents></declare>
</if>
<if>
<or>
<element name="r:step"/>
<element name="r:comment"/>
<element name="r:title"/>
</or>
<declare><contents>
<string/>
</contents></declare>
</if>
<if><element name="r:nutrition"/>
<declare>
<required>
<attribute name="protein"><stringtype ref="r:NUMBER"/></attribute>
<attribute name="carbohydrates"><stringtype ref="r:NUMBER"/></attribute>
<attribute name="fat"><stringtype ref="r:NUMBER"/></attribute>
<attribute name="calories"><stringtype ref="r:NUMBER"/></attribute>
</required>
<attribute name="alcohol"><stringtype ref="r:NUMBER"/></attribute>
</declare>
</if>
<stringtype id="r:DIGITS">
<repeat min="1">
<char min="0" max="9"/>
</repeat>
</stringtype>
<stringtype id="r:NUMBER">
<sequence>
<stringtype ref="r:DIGITS"/>
<optional>
<sequence>
<string value="."/>
<stringtype ref="r:DIGITS"/>
</sequence>
</optional>
</sequence>
</stringtype>
<rule id="r:ANYCONTENT">
<declare><contents>
<repeat><union><element/><string/></union></repeat>
</contents></declare>
</rule>
</dsd>
|
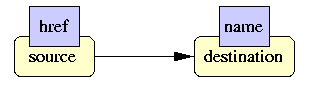
XLink es el lenguaje, definido en términos de marcas XML, que nos va a permitir introducir ligas en nuestros documentos XML, de modo que podamos relacionar unos archivos con otros.
Sería un grave error pensar en los enlaces como sólo los que conocemos del mundo HTML. En un enlace HTML solo hay DOS elementos relacionados. El primero es el origen, que se encuentra físicamente en la página de la persona que crea el enlace y que mantiene información de cómo actúa el enlace y hacia dónde apunta. El segundo elemento es el destino, que puede ser cualquier documento del mundo, apuntado sin que posiblemente tenga conocimiento de que está siendo enlazado desde una página.
Un XLink permite establecer una relación entre dos o más recursos en la Web, sin que necesariamente estos recursos sepan que están enlazados. Otra cosa es cómo se nota eso al navegar por páginas XML.
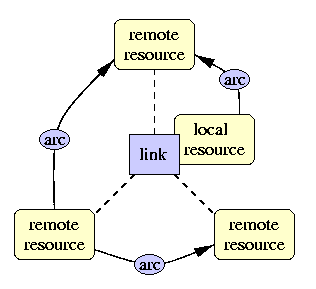
¿Qué tipos de enlaces puede tener XLINK?
Los primeros son los enlaces simples, que son básicamente como los que conocemos de HTML: un enlace desde un recurso local a uno remoto. Los otros son los enlaces extendidos, mucho más complejos pues permiten enlazar muchos recursos entre sí.
Ejemplo
<mi_documento xmlns:xlink="http://www.w3.org/XML/XLink/1.0">
...
<ver xlink:type="simple"
xlink:href="http://www.mi_colega.com/">
En este enlace puedes ver la página de un colega mío
</ver>
...
</mi_documento> |
Atributos en XLink
Show
Con este atributo podemos describir cómo se verá
el resultado del hecho de seguir el enlace. Sus posibles valores son: replace
(reemplaza el documento actual por aquel al que apunta el enlace), new
(abre un nuevo navegador con el documento destino) y parsed (el
contenido del texto apuntado se incluye en lugar del enlace y se procesa como
si fuera parte del mismo documento de origen).
<mi_documento xmlns:xlink="http://www.w3.org/XML/XLink/1.0">
...
<ver xlink:type="simple"
xlink:href="http://www.seat.com/"
xlink:show="replace">
Carga la página de SEAT
</ver>
...
<nueva-ventana xlink:type="simple"
xlink:href="http://wwwdi.ujaen.es/"
xlink:show="new">
Abre una nueva ventana de la Univ. de Jaén
</nueva-ventana>
...
<incluye xlink:type="simple"
xlink:href="mis_datos.xml"
xlink:show="parsed">
Incluye mis datos personales
</incluye>
...
</mi_documento> |
Actuate
Permite indicar cúando se debe proceder a buscar el destino
apuntado por un enlace. Los posibles valores son user (es decir,
cuando el usario pulse o dé alguna orden para seguir el enlace) y auto
(el enlace se sigue automáticamente; por ejemplo para redireccionar una
página, cargar una imagen o un fichero que debe ser incluido).
Enlaces Extendidos en XLink
Locator
Un enlace extendido puede tener más de dos recursos
que enlazar. Dichos recursos se especifican con el elemento locator.
<mi_documento xmlns:xlink="http://www.w3.org/XML/XLink/1.0">
...
<direcciones xlink:type="extended">
<locator xlink:type="locator"
xlink:href="http://realmadrid.com"
xlink:show="replace"
xlink:actuate="user"/>
<locator xlink:type="locator"
xlink:href="http://fcbarcelona.com"
xlink:show="new"
xlink:actuate="user"/>
<locator xlink:type="locator"
xlink:href="http://rcrecreativo.com"
xlink:show="new"
xlink:actuate="auto"/>
<locator xlink:type="locator"
xlink:href="http://athmadrid.com"
xlink:show="replace"
xlink:actuate="auto"/>
Los clubes de fútbol de hoy en día...
</direcciones>
...
</mi_documento> |
Visuaización de enlaces extendidos ? Agregación de ligas por parte de usuarios ?
Al igual que en otros lenguajes, en xml existe la capacidad de incluir otros fragmentos o documentos xml contenidos en otro lugar.
El XInclude standard define 2 elementos - include and fallback, y tres atributos - href, parse. xpointer. encoding, accept, y accept-language.
Attribute href
Descripción: le dice al procesador qué fragmentos deberá incluirse
File a.xml:
<a>
<xi:include href="b.xml"
xmlns:xi="http://www.w3.org/2001/XInclude"/>
</a>
|
File b.xml:
<b/> |
File a.xml after processing:
<a>
<b/>
</a>
|
Attribute parse = xml
Descripción: la inclusión se hará en xml, como en el ejemplo anterior
The file a.xml includes whole file b.xml.
File a.xml:
<a>
<xi:include href="b.xml" parse="xml"
xmlns:xi="http://www.w3.org/2001/XInclude"/>
</a>
|
File b.xml:
<b/> |
File a.xml after processing:
<a>
<b/>
</a>
|
Attribute parse = text
Descripción: la inclusion se hará en modo de secuencia de caracteres
The file a.xml includes whole file b.xml.
File a.xml:
<a>
<xi:include href="b.xml" parse="text"
xmlns:xi="http://www.w3.org/2001/XInclude"/>
</a>
|
File b.xml:
<b/> |
File a.xml after processing:
<a>
<b/>
</a>
|
Element fallback
Descripción: si ocurre un error con el include usar el fallback, como si fuera un "catch"
The file a.xml tries to include non-existent file.
File a.xml:
<a>
<xi:include href="non-existent.xml"
xmlns:xi="http://www.w3.org/2001/XInclude">
<xi:fallback>There are no files today ... </xi:fallback>
</xi:include>
</a>
|
File a.xml after processing:
<a>
There are no files today ...
</a>
|
Otro ejemplo de fallback
File a.xml:
<a>
<xi:include href="non-existent.xml"
xmlns:xi="http://www.w3.org/2001/XInclude">
<xi:fallback>
<xi:include href="alternative.xml">
<xi:fallback>There are no files today ... </xi:fallback>
</xi:include>
</xi:fallback>
</xi:include>
</a>
|
Empleando el tipo de parse=xml se puede hacer uso de xpointer para únicamente
incluir una porción de otro documento.
The file a.xml includes a paragraph with attribute id = 'p1' (attribute
id is of an ID-type) from file b.xml.
File a.xml:
<a>
<xi:include href="b.xml"
xpointer="p1"
parse="xml"
xmlns:xi="http://www.w3.org/2001/XInclude"/>
</a>
|
File b.xml:
<b>
<p id="p1">aaaa</p>
<p id="p2">bbbb</p>
</b>
|
File a.xml after processing:
<a>
<p id="p1">aaaa</p>
</a>
|
Nota importante:al usar xinclude revisar que no hayan recursiones que causen
ciclos infinitos.
XPath es un lenguaje empleado para seleccionar partes de un documento empleando path expressions
Un path expression es una secuencia de pasos separados por /
Similar a la estructura de directorios en un filesystem
El resultado de una path expression: un conjunto de valores que, junto con sus elementos/atributos hacen match con la ruta especificada
<bank-2> <account account-number=A-401 owners=C100 C102> <branch-name> Downtown </branch-name> <balance> 500 </balance> </account> <customer customer-id=C100 accounts=A-401> <customer-name>Joe </customer-name> <customer-street> Monroe </customer-street> <customer-city> Madison</customer-city> </customer> <customer customer-id=C102 accounts=A-401 A-402> <customer-name> Mary </customer-name> <customer-street> Erin </customer-street> <customer-city> Newark </customer-city> </customer> </bank-2> |
Ej. /bank-2/customer/customer-name
<customer-name>Joe</customer-name>
<customer-name>Mary</customer-name>
Ej. /bank-2/customer/customer-name/text( )
Joe
Mary
La "/" inicial indica la raíz del documento y las expresiones son
evaluadas de izquierda a derecha
Each step operates on the set of instances produced by the previous step
Las distintas partes puede incluir predicados, los cuales se encierran en [ ]
Ej. /bank-2/account[balance > 400]
recupera los elementos account que tengan un balance mayor que 400
/bank-2/account[balance]
recupera aquellos elementos account que poseen un subelemente balance
Los atributos son accesados con la @
Ej. /bank-2/account[balance > 400]/@account-number
recupera los números de cuenta de aquellas cuentas que tengan un balance > 400
El operator | es empleado para crear uniones
Ej. /bank-2/account/id(@owner) | /bank-2/loan/id(@borrower)
El operador // puede usarse para saltar muchos niveles
Ej. /bank-2//customer-name
Otros operadores en la definición de los paths pueden ser ".." y "*"
Existen muchas funciones que se pueden aplicar a los
valores de los elementos o bien a los atributos, los cuales tambien son evaluados
al momento de verificar el path
Core function library
Node-set functions:
| last() |
|
returns the context size |
| position() |
|
returns the context position |
| count(node-set) |
|
number of nodes in node-set |
| name(node-set) |
|
string representation of first node in node-set |
| ... |
|
... |
String functions:
| string(value) |
|
type cast to string |
| concat(string, string, ...) |
|
string concatenation |
| ... |
|
... |
Boolean functions:
| boolean(value) |
|
type cast to boolean |
| not(boolean) |
|
boolean negation |
| ... |
|
... |
Number functions:
| number(value) |
|
type cast to number |
| sum(node-set) |
|
sum of number value of each node in node-set |
| ... |
|
... |
No olvidar que la notación es la versión abreviada, pero existe la notación
basada en axes
Ej. child::section[position()<6] / descendant::cite[attribute::href="there"]
XPath 2.0
Actualmente existe el WorkingDraft de la versión 2.0 de XPath, que resulta ser un subconjunto de XSLT 2.0 y XQuery 1.0
Definición
XPointer es una extensión de XPath que nos permite cargar en un navegador o visualizador de documentos XML sólo aquellos elementos de un documento que nos interesen.
El equivalente en el mundo HTML es lo que se consigue con la
etiqueta de ancla <A NAME="nombre">, la cual nos
permite llamar a un documento con un nombre como: http://www.sitio.com/documento.html#etiqueta.
La idea que persigue XPointer es similar. XPointer va a permitir
añadir a una dirección del tipo http://www.sitio.com/documento.xml,
la terminación #xpointer(expresión),
donde expresión es una expresión XPath, con algunas
propiedades extra que no contempla el propio XPath.
Por desgracia, aún no hay muchas herramientas que soporten XPointer, de hecho es un estándar aún en discusión.
Uso de XPointer
Una expresión XPointer se añade a un URI (Uniform Resource Identifier), como puede ser un URL (Uniform Resource Locator) o un URN (Uniform Resource Name).
La idea es añadir al final del URI lo siguiente:
#xpointer( expresion )
Ejemplo de XPointer:
URI
-----------------------------------------------------------------
/ \
http://www.foo.org/bar.xml#xpointer(article/section[position()<=5])
| \ /|
| ---------------------------- |
\ XPointer expression /
\ /
-----------------------------------
XPointer fragment identifier
|
Un detalle muy importante a tener en cuenta es que se pueden concatenar expresiones XPointer que se evalúan de izquierda a derecha mientras devuelvan un conjunto vacío de nodos. Así, el siguiente ejemplo:
documento.xml#xpointer(/libro/capitulo[@public])xpointer(/libro/capitulo[@num="2"])
se buscaría por en primer lugar el conjunto de nodos delimitado
por /libro/capitulo, y solo en el caso de que no existiese ninguno,
se buscaría a continuación por /libro/capitulo[@num="2"].
XSL (eXtensible Stylesheet Language) consiste de 2 partes:
XSL Transformations (XSLT)
XSL Formatting Objects (XSL-FO).
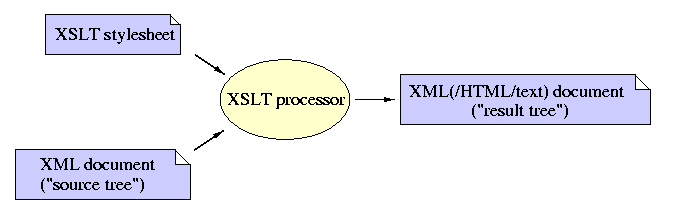
XSLT
Ejemplo de XSLT template con un match y select
<xsl:template match=/bank-2/customer>
<xsl:value-of select=customer-name/>
</xsl:template>
<xsl:template match=*/>
Los match attributes de xsl:template especifican un patrón en XPath
Dentro de cada template se procesan los resultados obtenidos en XPath
xsl:value-of selecciona e imprime el valor especificado ej. customer-name
Por default, en un documento XML, aquellos que no hacen match con ningun template pasan directamente a la salida. Por ello la última regla, para evitar esta situación
<xsl:template match=*/>
Ej.
<xsl:template match=/bank-2/customer>
<customer>
<xsl:value-of select=customer-name/>
</customer>
</xsl;template>
<xsl:template match=*/>
Output: <customer> Joe </customer> <customer> Mary </customer>
Ejemplo:
XML Document Input (figures.xml)
<?xml version="1.0"?>
<figures>
<circle x="20" y="10" r="20"/>
<rectangle x="-3" y="4" w="5" h="36"/>
<ellipse x="-5" y="6" w="30" h="50"/>
<rectangle x="7" y="23" w="58" h="45"/>
<circle x="-2" y="5" r="35"/>
<ellipse x="-10" y="-8" w="45" h="30"/>
</figures>
XSL Style Sheet
<?xml version="1.0"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<HTML>
<HEAD><TITLE>Figures</TITLE></HEAD>
<BODY>
<xsl:apply-templates/>
</BODY>
</HTML>
</xsl:template>
<xsl:template match="figures">
<TABLE>
<TR><TD>X</TD><TD>Y</TD></TR>
<xsl:apply-templates select="circle"/>
</TABLE>
</xsl:template>
<xsl:template match="circle">
<TR> <TD><xsl:value-of select="@x"/></TD>
<TD><xsl:value-of select="@y"/></TD>
</TR>
</xsl:template>
</xsl:stylesheet>
HTML output file:
<HTML> <HEAD> <TITLE>Figures</TITLE> </HEAD> <BODY> <TABLE> <TR> <TD>X</TD><TD>Y</TD> </TR> <TR> <TD>20</TD><TD>10</TD> </TR> <TR> <TD>-2</TD><TD>5</TD> </TR> </TABLE> </BODY> </HTML>
Existe una directiva xsl:sort que permite ordenar los resultados que hacen match
Ej.
<xsl:template
match="animals">
<animals>
<xsl:apply-templates>
<xsl:sort data-type="number" select="@legs"/>
</xsl:apply-templates>
</animals>
Procesando hojas de estilo
Un documento xml puede hacer referencia a una hoja de estilo para que un navegador o visualizador pueda formatear dicho documento y desplegarlo correctamente
| <?xml-stylesheet type="text/xsl" href="foo.xsl"?> |
Nota: Algunos browsers no tienen asociada la extensión/mimetype
xsl marcarán un error, la solución es nombrar la hoja de estilo
con extensión xml.
XML document (students.xml)
XSLT style sheet (students.xsl)
Xalan jar file (xalan.jar) de Apache
java -classpath "xalan.jar" org.apache.xalan.xslt.Process
-IN students.xml -XSL students.xsl -OUT students.html
1:import java.io.FileNotFoundException; 2:import java.io.FileWriter; 3:import java.io.StringWriter; 4:import java.io.IOException; 5:import javax.xml.transform.Transformer; 6:import javax.xml.transform.TransformerConfigurationException; 7:import javax.xml.transform.TransformerException; 8:import javax.xml.transform.TransformerFactory; 9:import javax.xml.transform.stream.StreamResult; 10:import javax.xml.transform.stream.StreamSource; 11:import mx.udlap.ict.util.*; 12:public class SimpleTransform 13:{ 14:public static void main(String[] args) 15: throws TransformerException, TransformerConfigurationException, 16: FileNotFoundException, IOException 17:{ 18: 19: 20: TransformerFactory tFactory = TransformerFactory.newInstance(); 21: 22: Transformer transformer = tFactory.newTransformer(new StreamSource("students.xsl")); 23: 24: String out=new String(); 25: StringWriter sw=new StringWriter(); 26: transformer.transform(new StreamSource("students.xml"),new StreamResult(sw)); 27: out=sw.toString(); 28: System.out.println(out); 29: 30:} 31:} 32: |
Output File (students.html)
<HTML>
<HEAD>
<TITLE>Name of students</TITLE>
</HEAD>
<BODY>
<P>John Smith</P>
<P>George Lucas</P>
<P>Elizabeth Roberts</P>
</BODY>
</HTML>
Provee control exacto y detallado del "layout" de los objectos
De manera general un FO esta compuesto por:
layout masters que define el layout de la(s) página
Páginas agrupadaes en page sequences, recordar que si el contenido no cabe en una página automáticamente se usará también la siguiente
top-magin
left-margin right-margin
bottom-margin |
|||||||||
Ejemplos usando FOP
1:<?xml version="1.0" encoding="utf-8"?> 2: 3:<fo:root font-family="Times Roman" font-size="12pt" text-align="center" xmlns:fo="http://www.w3.org/1999/XSL/Format"> 4: 5:<fo:layout-master-set> 6: 7:<fo:simple-page-master master-name="mypage" 8: margin-top="20pt" margin-bottom="20pt" margin-left="20pt" margin-right="20pt"> 9: <fo:region-body/> 10:</fo:simple-page-master> 11: 12: 13: 14:</fo:layout-master-set> 15: 16:<fo:page-sequence master-reference="mypage"> 17: 18:<fo:flow flow-name="xsl-region-body"> 19: <fo:block> 20: Universidad de las Americas Puebla 21: </fo:block> 22: <fo:block> 23: <fo:external-graphic src="url(../graphics/udla-escudo.png)"/> 24: </fo:block> 25:</fo:flow> 26:</fo:page-sequence> 27: 28:<fo:page-sequence master-reference="mypage"> 29: 30:<fo:flow flow-name="xsl-region-body"> 31: <fo:block> 32: Carlos Proal Aguilar 33: </fo:block> 34: <fo:block> 35: <fo:external-graphic src="url(../graphics/charlieBrown_alone.gif)"/> 36: </fo:block> 37:</fo:flow> 38:</fo:page-sequence> 39: 40: 41: 42:</fo:root> 43: |
> ./fop.sh /home/digital/fop-0.20.5-bin/fop-0.20.5/examples/fo/basic/simplesample.fo simplesample.pdf
1:<?xml version="1.0" encoding="utf-8"?> 2: 3:<fo:root font-family="Times Roman" font-size="12pt" text-align="center" xmlns:fo="http://www.w3.org/1999/XSL/Format"> 4: 5:<fo:layout-master-set> 6: <fo:simple-page-master master-name="mypage" 7: margin-top="0pt" margin-bottom="0pt" margin-left="0pt" margin-right="0pt"> 8: <fo:region-body/> 9: </fo:simple-page-master> 10:</fo:layout-master-set> 11: 12:<fo:page-sequence master-reference="mypage"> 13:<fo:flow flow-name="xsl-region-body"> 14: <fo:block> 15: <fo:external-graphic src="url(../graphics/xml_feather.gif)"/> 16: </fo:block> 17: <fo:block> 18: <fo:external-graphic src="url(../graphics/xml_feather_transparent.gif)"/> 19: </fo:block> 20:</fo:flow> 21:</fo:page-sequence> 22:<fo:page-sequence master-reference="mypage"> 23:<fo:flow flow-name="xsl-region-body"> 24:<fo:block-container 25: position="absolute" 26: width="130mm" 27: height="120mm" 28: left="20mm" 29: top="20mm" 30: background-color="#00FF33" 31: padding="4mm" 32: reference-orientation="90"> 33: <fo:block>Positioned block container</fo:block> 34: <fo:block> 35: <fo:external-graphic src="url(../graphics/linux.bmp)"/> 36: </fo:block> 37:</fo:block-container> 38: <fo:block-container 39: position="absolute" 40: width="130mm" 41: height="120mm" 42: left="25mm" 43: top="20mm" 44: padding="4mm" 45: reference-orientation="90"> 46: <fo:block> Positioned block container</fo:block> 47: <fo:block> Positioned block container</fo:block> 48: <fo:block> 49: <fo:external-graphic src="url(../graphics/xml_feather_transparent.gif)"/> 50: </fo:block> 51:</fo:block-container> 52:</fo:flow> 53:</fo:page-sequence> 54: 55:<fo:page-sequence master-reference="mypage"> 56:<fo:flow flow-name="xsl-region-body"> 57:<fo:block-container 58: position="absolute" 59: left="50mm" 60: top="50mm" 61: width="215.9mm" 62: height="279.4mm" 63: padding="0mm" 64: reference-orientation="90"> 65: <fo:block> 66: <fo:external-graphic src="url(../graphics/linux.bmp)"/> 67: </fo:block> 68:</fo:block-container> 69: <fo:block-container 70: position="absolute" 71: left="0mm" 72: top="0mm" 73: width="215.9mm" 74: height="279.4mm" 75: padding="0mm" 76: reference-orientation="90"> 77: <fo:block margin-top="0pt"> 78: <fo:external-graphic src="url(../graphics/Image-17-transparent.gif)"/> 79: </fo:block> 80:</fo:block-container> 81:</fo:flow> 82:</fo:page-sequence> 83: 84:<fo:page-sequence master-reference="mypage"> 85:<fo:flow flow-name="xsl-region-body"> 86: <fo:block margin-top="0pt"> 87: <fo:external-graphic src="url(../graphics/Image-17.png)"/> 88: </fo:block> 89:</fo:flow> 90:</fo:page-sequence> 91: 92: 93:</fo:root> 94: |
> ./fop.sh /home/digital/fop-0.20.5-bin/fop-0.20.5/examples/fo/basic/myimages.fo myimages.pdf
El API de FOP permite hacer los layouts programáticamente
1:// Java 2:import java.io.BufferedOutputStream; 3:import java.io.File; 4:import java.io.FileOutputStream; 5:import java.io.IOException; 6:import java.io.OutputStream; 7: 8://JAXP 9:import javax.xml.transform.Transformer; 10:import javax.xml.transform.TransformerFactory; 11:import javax.xml.transform.Source; 12:import javax.xml.transform.Result; 13:import javax.xml.transform.stream.StreamSource; 14:import javax.xml.transform.sax.SAXResult; 15: 16: 17:// FOP 18:import org.apache.fop.apps.Driver; 19:import org.apache.fop.apps.FOPException; 20: 21:/** 22: * This class demonstrates the conversion of an FO file to PDF using FOP. 23: */ 24:public class ExampleFO2PDF { 25: 26: /** 27: * Converts an FO file to a PDF file using FOP 28: * @param fo the FO file 29: * @param pdf the target PDF file 30: * @throws IOException In case of an I/O problem 31: * @throws FOPException In case of a FOP problem 32: */ 33: public void convertFO2PDF(File fo, File pdf) throws IOException, FOPException { 34: 35: OutputStream out = null; 36: 37: try { 38: // Construct driver and setup output format 39: Driver driver = new Driver(); 40: driver.setRenderer(Driver.RENDER_PDF); 41: 42: // Setup output stream. Note: Using BufferedOutputStream 43: // for performance reasons (helpful with FileOutputStreams). 44: out = new FileOutputStream(pdf); 45: out = new BufferedOutputStream(out); 46: driver.setOutputStream(out); 47: 48: // Setup JAXP using identity transformer 49: TransformerFactory factory = TransformerFactory.newInstance(); 50: Transformer transformer = factory.newTransformer(); // identity transformer 51: 52: // Setup input stream 53: Source src = new StreamSource(fo); 54: 55: // Resulting SAX events (the generated FO) must be piped through to FOP 56: Result res = new SAXResult(driver.getContentHandler()); 57: 58: // Start XSLT transformation and FOP processing 59: transformer.transform(src, res); 60: 61: } catch (Exception e) { 62: e.printStackTrace(System.err); 63: System.exit(-1); 64: } finally { 65: out.close(); 66: } 67: } 68: 69: 70: /** 71: * Main method. 72: * @param args command-line arguments 73: */ 74: public static void main(String[] args) { 75: try { 76: System.out.println("FOP ExampleFO2PDF\n"); 77: System.out.println("Preparing..."); 78: 79: //Setup directories 80: File baseDir = new File("."); 81: File outDir = new File(baseDir, "out"); 82: outDir.mkdirs(); 83: 84: //Setup input and output files 85: File fofile = new File(baseDir, "simplesample.fo"); 86: File pdffile = new File(outDir, "simplesample.pdf"); 87: 88: System.out.println("Input: XSL-FO (" + fofile + ")"); 89: System.out.println("Output: PDF (" + pdffile + ")"); 90: System.out.println(); 91: System.out.println("Transforming..."); 92: 93: ExampleFO2PDF app = new ExampleFO2PDF(); 94: app.convertFO2PDF(fofile, pdffile); 95: 96: System.out.println("Success!"); 97: } catch (Exception e) { 98: e.printStackTrace(System.err); 99: System.exit(-1); 100: } 101: } 102:} 103: |
Se derivó de las propuestas previas:
* XML-QL
* YATL
* Lorel
* Quilt
Se basa en XPath y en los XML Schema datatypes
Ejemplo:
let $i := 42 (: This is also a comment. :) |
<x>(: This is not a comment. :)</x> |
Comments
| (: Esto es un comentario :) |
Prolog
declare function foo($param as xs:integer) as xs:string external; declare variable $var as xs:decimal external; |
Constructors
{{ 1 + 1 = { 1+1 }}}
</add><add>{ 1 + 1 = 2 }</add>
<employee empid="{$id}">
<name>{$name}</name>
{$job}
<deptno>{$deptno}</deptno>
<salary>{$SGMLspecialist+100000}</salary>
</employee>
<employee empid="12345">
<name>John Doe</name>
<job>XML specialist</job>
<deptno>187</deptno>
<salary>125000</salary>
</employee>
document {
element foo {
attribute bar { 1 + 1 }
text { "baz" }
<x xmlns='urn:x'>Ordinary XML can be
intermixed with the alternate syntax</x>
}
}
intermixed with the alternate syntax</x></foo>
declare function first( element $f)
return element
{
let $firstChild := $f/*[1]
return
element{ xf:name($firstChild) }
{ xf:data($firstChild/@*[1]) }
} |
first(<employee id="998359">
<status value="retired"/>
<name>Alan Greene</name>
</employee>)
--> <status>retired</status>
|
Built-in Functions (lista completa)
De propósito general
count(("a", 2, "c"))
Numéricas
min((2, 1, 3, -100)) -100 round(9 div 2) 5 round-half-to-even(9 div 2) 4
Booleanas
then "negative"
else if (expr > 0)
then "positive"
else "zero"
Caracteres
string-length("abcde") 5 substring("abcde", 3) cde substring("abcde", 2, 3) bcd concat("ab", "cd", "", "e") abcde string-join(("ab","cd","","e"), "") abcde string-join(("ab","cd","","e"), "x") abxcdxxe contains("abcde", "e") true replace("abcde", "a.*d", "x") xe replace("abcde", "([ab][cd])+", "x") axde normalize-space(" a b cd e ") a b cd e
FLWOR (for, let, where,order, return)
let $dept := document("depts.xml")
let $emp := document("employees.xml")
for $e in $emp//employee
$d in $dept//department
where $e/dept eq $d/name
return
<employee name="{data($e/name)}"
dept="{data($d/dept)}"/>
|
-->
<employee name="Albert Jones"
dept="accounting"/>
<employee name="Gloria French"
dept="accounting"/>
<employee name="Clark Hill"
dept="security"/>
|
for $i in doc("orders.xml")//Customer (
let $name := concat($i/@FirstName,$i/@LastName)
where $i/@ZipCode = 91126
order by $i/@LastName
return
<Customer Name="{$name}">
{ $i//Order }
</Customer>
Joins
for $i in doc("one.xml")//fish, |
Más ejemplos
document("recipes.xml")//recipe[title="Ricotta Pie"]//ingredient[@amount] |
for $d in document("depts.xml")//deptno
let $e := document("emps.xml")//employee[deptno = $d]
|
Para el empleo de XQuery sobre documentos XML se puede emplear Saxon
Namespace
El namespace correspondiente a Xupdate es descrito en el URI http://www.xmldb.org/xupdate.
Selects
Toda actualización, al igual que en cualquier base de datos, requiere una selección de datos sobre los cuales aplicar dichos cambios; XUpdate continua con el estándar de utilizar XPath para dicho propósito.
Modification
Toda modificación debe estar contenida en un elemento xupdate:modifications el cual debe contener un atributo indicando la version de XUpdate necesaria (ej 1.0).
A su vez, el elemento modifications debe contener alguno de los siguientes elementos, dependiendo del tipo de cambio a realizar
xupdate:insert-before
xupdate:insert-after
xupdate:append
xupdate:update
xupdate:remove
xupdate:rename
xupdate:variable
xupdate:value-of
xupdate:if
<?xml version="1.0"?>
<addresses version="1.0">
<address id="1">
<fullname>Andreas Laux</fullname>
<born day='1' month='12' year='1978'/>
<town>Leipzig</town>
<country>Germany</country>
</address>
</addresses>
|
<?xml version="1.0"?>
<xupdate:modifications version="1.0"
xmlns:xupdate="http://www.xmldb.org/xupdate">
<xupdate:insert-after select="/addresses/address[1]" >
<xupdate:element name="address">
<xupdate:attribute name="id">2</xupdate:attribute>
<fullname>Lars Martin</fullname>
<born day='2' month='12' year='1974'/>
<town>Leizig</town>
<country>Germany</country>
</xupdate:element>
</xupdate:insert-after>
</xupdate:modifications>
|
<?xml version="1.0"?>
<addresses version="1.0">
<address id="1">
<fullname>Andreas Laux</fullname>
<born day='1' month='12' year='1978'/>
<town>Leipzig</town>
<country>Germany</country>
</address>
<address id="2">
<fullname>Lars Martin</fullname>
<born day='2' month='12' year='1974'/>
<town>Leizig</town>
<country>Germany</country>
</address>
</addresses>
|
Inserts
xupdate:insert-before inserta un nodo como el hermano predecesor del nodo seleccionado
xupdate:insert-after inserta un nodo como el hermano sucesor del nodo seleccionado
Estos elementos deben contener alguno de los siguientes elementos:
xupdate:element
<xupdate:element name="address">
<town>San Francisco</town>
</xupdate:element>
|
<address>
<town>San Francisco</town>
</address> |
xupdate:attribute
<xupdate:element name="address">
<xupdate:attribute name="id">2</xupdate:attribute>
</xupdate:element>
|
<address id="2"/> |
xupdate:text
xupdate:processing-instruction
<xupdate:processing-instruction name="cocoon-process">
type="xsp"
</xupdate:processing-instruction> |
<?cocoon-process type="xsp"?> |
xupdate:comment
<xupdate:comment> This element is automatically generated. </xupdate:comment> |
<!--This element is automatically generated. --> |
Appends
Se emplea para agregar un nodo como hijo de otro nodo
Debe contener algunos de los siguientes elementos:
xupdate:element
xupdate:attribute
xupdate:text
xupdate:processing-instruction
xupdate:comment
<xupdate:append select="/addresses" child="last()">
<xupdate:element name="address">
<town>San Francisco</town>
</xupdate:element>
</xupdate:append>
|
<addresses> <address> <town>Los Angeles</town> </address> <address> <town>San Francisco</town> </address> </addresses> |
Updates
Se emplea para actualizar el contenido de algun nodo
<xupdate:update select="/addresses/address[2]/town"> New York </xupdate:update> |
<addresses>
<address>
<town>Los Angeles</town>
</address>
<address>
<town>New York</town>
</address>
</addresses>
|
Remove
<xupdate:remove select="/addresses/address[1]"/> |
<addresses>
<address>
<town>New York</town>
</address>
</addresses> |
Rename
<xupdate:rename select="/addresses/address/town"> city </xupdate:rename> |
<addresses>
<address>
<city>New York</city>
</address>
</addresses> |
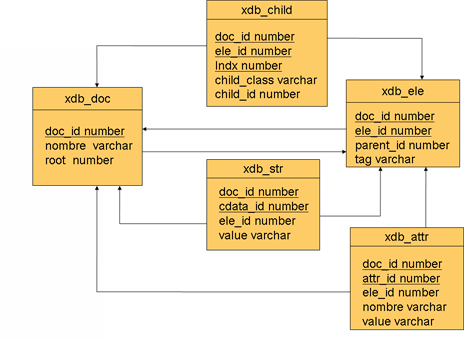
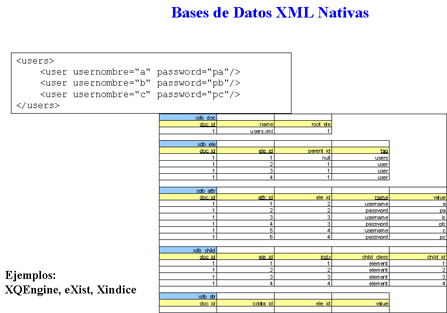
7.3 XML Databases
7.3.1 Antecedentes
7.3.2 Definición
Hablar de documentos XML es hablar de 2 categorías
Para los documentos centrados en los datos, podemos pensar en datos estructurados que pueden extraerse del documento e indexarse con alguna base de datos convencionalPor otro lado para los datos centrados en el documento el reto no es tan trivial ya que se pretende hacer consultas pero no solo sobre el contenido, sino también sobre la estructura del documento.De modo que una base de datos XML es aquella que define un modelo lógico de un documento XML y almacena y recupera documentos de acuerdo a ese modelo.
7.3.3 Tipos de Bases de Datos XMLXML Enabled Databases (Bases de datos habilitadas para XML): son aquellas que desglosan la información de un documento XML en su correspondiente esquema relacional o de objetos
Product
Developer
License
DB Type
Access 2002
Microsoft
Commercial
Relational
Cache
InterSystems Corp.
Commercial
Multi-valued
DB2
IBM
Commercial
Relational
eXtremeDB
McObject
Commercial
Navigational
FileMaker
FileMaker
Commercial
FileMaker
FoxPro
Microsoft
Commercial
Relational
Informix
IBM
Commercial
Relational
Matisse
Matisse Software
Commercial
Object-oriented
Objectivity/DB
Objectivity
Commercial
Object-oriented
OpenInsight
Revelation Software
Commercial
Multi-valued
Oracle 8i, 9i
Oracle
Commercial
Relational
SQL Server 2000
Microsoft
Commercial
Relational
Sybase ASE 12.5
Sybase
Commercial
Relational
Versant enJin
Versant Corp.
Commercial
Object-oriented
En un inicio, las bases de datos habilitadas para XML convertían la información a un esquema relacional y los queries se hacían en SQL, hoy día es posible no solo recuperar los resultados formateados en XML, sino interrogar a ese esquema relacional usando XPath o XQuery.
XML Native Databases (Bases de datos nativas de XML): son aquellas que respetan la estructura del documento, se pueden hacer consultas sobre dicha estructura y es posible recuperar el documento tal como fue insertado originalmente.
Product
Developer
License
DB Type
4Suite, 4Suite Server
FourThought
Open Source
Object-oriented
Birdstep RDM XML
Birdstep
Commercial
Object-oriented
Centor Interaction Server
Centor Software Corp.
Commercial
Proprietary
Cerisent XQE
Cerisent
Commercial
Proprietary(?)
Coherity XML Database
Coherity
Commercial
Proprietary
DBDOM
K. Ari Krupnikov
Open Source
Relational
dbXML
dbXML Group
Commercial
Proprietary
DOM-Safe
Ellipsis
Commercial
Proprietary
eXist
Wolfgang Meier
Open Source
Relational
eXtc
M/Gateway Developments Ltd.
Commercial
Multi-valued
eXtensible Information Server (XIS)
eXcelon Corp.
Commercial
Object-oriented (ObjectStore). Relational and other data through Data Junction
GoXML DB
XML Global
Commercial
Proprietary (Text-based)
Infonyte DB
Infonyte
Commercial
Proprietary (Model-based)
Ipedo XML Database
Ipedo
Commercial
Proprietary
Lore
Stanford University
Research
Semi-structured
Lucid XML Data Manager
Ludic'i.t.
Commercial
Proprietary
MindSuite XDB
Wired Minds
Commercial
Object-oriented
Natix
data ex machina
Commercial
File system(?)
Neocore XML Management System
NeoCore
Commercial
Proprietary
ozone
ozone-db.org
Open Source
Object-oriented
Sekaiju / Yggdrasill
Media Fusion
Commercial
Proprietary
SQL/XML-IMDB
QuiLogic
Commercial
Proprietary (native XML and relational)
Tamino
Software AG
Commercial
Proprietary. Relational through ODBC.
TeraText DBS
TeraText Solutions
Commercial
Proprietary
TEXTML Server
IXIA, Inc.
Commercial
Proprietary (Text-based)
TigerLogic XDMS
Raining Data
Commercial
Pick
TOTAL XML
Cincom
Commercial
Object-relational?
Virtuoso
OpenLink Software
Commercial
Proprietary. Relational through ODBC
XDBM
Matthew Parry, Paul Sokolovsky
Open Source
Proprietary (Model-based)
XDB
ZVON.org
Open Source
Relational (PostgreSQL only?)
X-Hive/DB
X-Hive Corporation
Commercial
Object-oriented (Objectivity/DB). Relational through JDBC
Xindice
Apache Software Foundation
Open Source
Proprietary (Model-based)
Xyleme Zone Server
Xyleme SA
Commercial
Proprietary
7.3.4 Programando con una XML DatabaseAfortunadamente el grupo XMLDB ha propuesto un API que todos los proveedores deben implementarAl igual que con otras aplicaciones el API simplemente define un conjunto de interfaces que cada proveedor implementa:
org.xmldb.api
Interfaces
DatabaseManagerorg.xmldb.api.base
Interfaces
Collection
Configurable
Database
Resource
ResourceIterator
ResourceSet
ServiceClasses
ErrorCodesExceptions
XMLDBExceptionorg.xmldb.api.modules
Interfaces
BinaryResource
CollectionManagementService
TransactionService
XMLResource
XPathQueryService
XUpdateQueryServiceEs importante recordar:
Una colección es un conjunto de documentos (una base de datos)
Un recurso es un documento dentro de la colección
Un servicio es una facilidad que permite hacer hacer acciones que van desde búsquedas hasta inserciones, etc.
Imports:import org.xmldb.api.base.*;
import org.xmldb.api.modules.*;
import org.xmldb.api.*;El driver puede ser:"org.exist.xmldb.DatabaseImpl""org.apache.xindice.client.xmldb.DatabaseImpl"El url puede serxmldb:exist://localhost:8080/exist/xmlrpc/db/thesisxmldb:xindice://localhost:4080/db/thesis
Agregando un documento
Recuperación de un documento
Ejecutando una consulta
Ejecutando una actualización
*Los resultados estarán expresados en XML
7.3.5 Utilizando una XML DatabaseBásicamente la utilización radica en los siguientes pasos:
- Escoger una XMLDatabase (exist y xindice son los más recomendables)
- Instalarla, configurarla y de preferencia crear usuarios y permisos
- Crear un DTD que deberán seguir todos los documentos de la colección
- Formular los posibles queries en XPath que deseamos obtener de la colección
- Crear las aplicaciones que ejecuten las distintas acciones en la XMLDB
- Diseñar las XSL que den formato a los resultados de las búsquedas
- Integrar todas las partes