1. Introducción
1.1 Información y su rol en los sistemas
1.1.1 Crecimiento
Hoy en día la información se ha convertido en el arma más poderosa que cualquier país desea tener.
La información se encuentra en todas partes y crece a cada momento.
Volúmenes de datos
| KB | ~10^3: 1 página tecleada |
| MB | ~10^6: texto de 1 libro |
| GB | ~10^9: sinfonías, libros |
| TB | ~10^12: una biblioteca |
| Peta-byte | ~10^15: bibliotecas EEUU |
| Exa-byte | ~10^18: datos de 1 año |
| Zeta-byte | ~10^21 |
| Yotta-byte | ~10^24 |
¿Cuántos datos? y ¿Cuánta información?
• En 2002 se produjeron 5 exabytes (10^18 bytes), incluyendo impresos, películas, y medios magnéticos y ópticos
• 800 MB por persona (considerando 6.3 mil millones de humanos)
• Biblioteca del Congreso (LC) digitalizada = 136 TB, entonces 5 EB = 37,000 LCs
• 92% discos duros, 7% películas, .01% papel, 0.002% medios ópticos
• EE UU produce 40% de los datos almacenados
Fuente: http://www.sims.berkeley.edu/research/projects/how-much-info-2003/
¿Crecimiento exponencial?
• De 1999 a 2003, crecimiento anual de 30%
• El uso de papel sigue creciendo
• La mayoría de los datos generados no se almacenan en publicaciones formales
• El flujo de datos en líneas telefónicas, radio y TV fue de casi 18 EB (no todo es nuevo)
• WWW = 170 TB
• Email = 400,000 TB por año
• Chat = 274 TB por año
Fuente: http://www.sims.berkeley.edu/research/projects/how-much-info-2003/
Integración de contenidos digitales
• Oportunidades
– Hoy, aun los materiales impresos son primero digitales
– Tesis, reportes técnicos, datos experimentales, notas de cursos, memorias de congresos• Impacto
– Comunidad global de autores y editores
– Agilidad en la comunicación de resultados• Problemas
– Distribución, heterogeneidad de formatos, calidad, idioma, derechos de autor
Digitalización de materiales analógicos
• Oportunidades
– Libros antiguos, correspondencia, archivos
– Digitalización “aérea”
– OCR cada vez más preciso
– Disponibilidad de expertos en materiales• Impacto
– Acceso, preservación, búsquedas, comparaciones
• Problemas
– Selección, materiales deteriorados, frágiles, tipografía antigua, lenguaje antiguo, manuscritos, derechos de autor
Demasiada información.....algunas soluciones
• Construcción de colecciones digitales confiables
• Técnicas de recuperación de información
• Descripción de documentos (metadatos)
• Servidores de alto desempeño
• Mayor ancho de banda (ej. I2)
• Servicios para usar y enriquecer colecciones
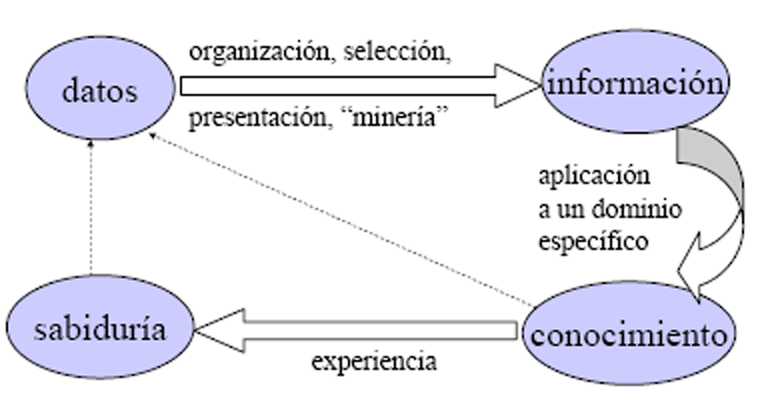
1.1.2 Dato, Información, Conocimiento y Sabiduría
Definiciones
• Dato: Una representación física de la realidad– Ejemplos: números, letras, diagramas, sonidos, videos
• Información: Datos a los que se ha asociado un significado– Ejemplos: Estados financieros, interpretación musical, conferencia, presentación gráfica
• Conocimiento: Información organizada y accesible para su aplicación a situaciones y problemas específicos• Sabiduría: Conjunto de conocimientos aplicables a situaciones y problemas diversos
 |
1.2 Datos vs Información
1.2.1 Administración de Datos
Definición
Mecanismos para el almacenamiento, recuperación oportuna y mantenimiento de datos
Recuperación de Datos
- Consiste en determinar que documentos contienen las llaves del query en el documento
- No resuelve algunos problemas ej. el problema de recuperar información acerca de un tema
Características
- Almacenamiento
- Indexamiento
- Bases de datos
- Recuperación
- Consultas estructuradas
- Resultados exactos
- Formateo
1.2.2 Administración de información
Definición
Dada una consulta, la meta es recuperar la información relevante para el usuario.
Recuperación de Información
- Analizar el contenido de una colección de documentos a través
de términos
- Sinónimos, términos con significado cercano (serpiente y reptil)
- Polisemia, términos con significado dependiente del contexto (interés, banco)
- Refinar consultas para precisar el contexto de referencia
- La representación y organización de la información deben proveer al usuario un fácil acceso a sus interes personales
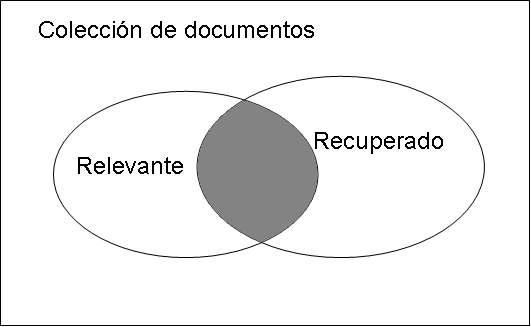 |
Precisión (Precision): cuántos documentos recuperados son relevantes
= Relevantes recuperados / Recuperados
Cobertura (Recall): cuántos documentos relevantes se recuperaron
= Relevantes recuperados / Relevantes
Características
- Almacenamiento
- Bases de datos
- Indices
- Listas invertidas
- Colecciones de archivos
- Recuperación
- Consultas imprecisas
- Leguajes basados en palabras clave
- Resultados aproximados (evaluación de pertinencia)
- Algoritmos de recuperación
1.2.3 RD vs. RI: comparación
RD |
RI |
|
| Match | exacto |
parcial |
| Inferencia | deducción |
inducción |
| Modelo | determinístico |
probabilístico |
| Consulta | artificial |
natural |
| Especificación | completa |
incompleta |
| Resultados | match |
relevancia |
1.2.4 Administración de Conocimiento
Técnicas de extracción de conocimiento (reglas, correlaciones,
excepciones, tendencias) a partir de archivos o de bases de datos
Correlación de grandes conjuntos de datos diseminados en centros con experiencia amplia en algún dominio
- Producir reglas de evolución de un histórico (mercado bursátil, el desarrollo de células patógenas)
- Predecir riesgos en el medio ambiente (correlación de diferentes temas en una base de datos geográfica)
1.3 Información y Estructura.
En la sección anterior se hizo una distinción entre datos e información, la cual ha surgido más bien sobre la marcha, cuando las personas se dieron cuenta de la dificultad de contestar a determinados cuestionamientos, por ejemplo por el contenido de documentos. Pero existe una clasificación científica más precisa que nos ayuda a definir los distintos tipos de datos.
1.3.1 Datos estructurados
Son aquellos atributos o variables fuertemente tipados (int, float, string) Cada atributo en una relación está definido para todos los registros Están organizados de alguna manera Ejemplos: registros, base de datos relacional (tabla 1.1)
Tabla 1.1 Datos Estructurados
| nombre char(10) |
cumpleaños date |
sueldo int |
| Carlos |
1980-08-13 |
5000 |
| Juan |
1977-02-23 |
7500 |
1.3.2 Datos no estructurados
- No poseen definiciones de tipos
- No organizados de acuerdo a ningún patrón
- No existe el concepto de variables o atributos
- Ejemplos: documentos de texto sin estructura, e-mails, páginas de html (tabla 1.2)
Tabla 1.2 Datos No Estructurados
| Carlos nació el 13 de Agosto de 1980. El tiene un sueldo de 5000. Alguien más nació el 23 de Febrero de 1977, su nombre es Juan y su salario es de 7500 |
Como se puede observar no existe una manera automática de poder analizar este dato para hacer cuestionamientos, a esto nos referíamos en la sección anterior como información.
1.3.3 Datos semiestructurados
- Lo que sea entre estructurado y no estructurado
- Variables pobremente tipadas (x=1 es válido y x=hola también es válido)
- Un registro no necesariamente tiene que tener todos sus atributos definidos. Mientras por ejemplo en una base de datos relacional un campo debe establecerse como NULL cuando no se tiene, en un ambiente de datos semiestructurados basta con omitir dicho atributo.
- Un atributo de un registro puede ser otro registro
- No existe necesariamente una diferencia entre un identificador de un campo y el valor mismo de este.
- Ejemplos: documentos SGML y XML
Los datos semiestructurados pueden ser representados como:
- Arbol (figura 1.1)
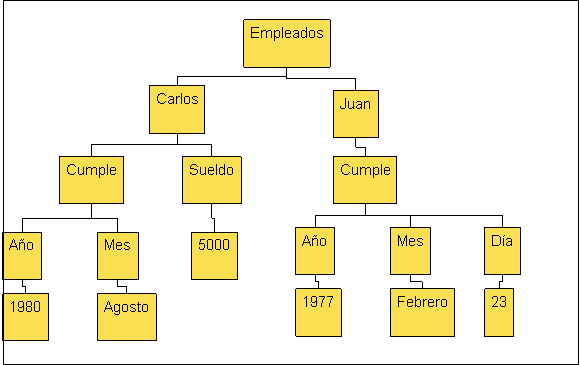
Figura 1.1 Representación datos semiestructurados en árbol
- Texto indentado (tabla 1.3)
Tabla 1.3 Representación datos semiestructurados texto indentado
| Carlos Cumpleaños 1980 Agosto 13 Sueldo $5,000 Juan Cumpleaños 1977 Febrero |
Lenguaje de Marcado (Markup Language) (tabla 1.4)
Tabla 1.4 Representación datos semiestructurados lenguaje marcado
| <compania>
<nombre>Carlos</nombre> <extension>5513</extension> <departamento>Ventas</departamento> <sueldo>5000</sueldo>
<nombre>Alfredo</nombre> <extension>2666</extension> <oficina>312</oficina> <departamento>Ejecutivo</departamento> <sueldo>Director</sueldo>
</compania> |
Otra característica de los datos semiestructurados es que no son creados necesariamente con la intención de ser analizados o más aún de ser interrogados, por ejemplo las páginas de HTML no son creadas con ese propósito mientras que archivos en XML si lo son.
1.3.4 Relación de conceptos
| Tipo de dato | Concepto |
estructurado |
dato |
| no estructurado | información |
| semi-estructurado | datos e información |
1.4 Administración de la Información
Despues de haber comentado las diferencias entre datos e información, analizado los distintos tipos de datos podemos concluir:
- Los datos y la información son el centro de las aplicaciones de hoy día, simplemente las organizaciones y negocios no podrían funcionar sin ellos.
- De alguna manera el negocio de hoy día es las administración de la información.
- Sin los datos la industria no tendría la habilidad de manejar finanzas, conducir transacciones o contactar a sus clientes.
- Mientras mejor sean diseñados y utilizados los datos mejor será la organización y la capacidad de competir.
- La administración de la información es una disciplina que implica una planeación, implementación, compartición y mantenimiento de datos.
- Por todo lo anterior, es importante estudiar técnicas "avanzadas" que permitar lidear con:
- Grandes volúmenes de información
- Distintos tipos de datos
- Distintas necesidades de modelado y representación
- Alta disponibilidad y alto desempeño
- Explotar los datos para poder generar información, conocimiento y sabiduría.