10. Combinación de modelos
10.1 Introducción
En las secciones anteriores se han mostrado los diferentes tipos de datos con respecto a su estructura, así mismo se han mostrado algunas de las herramientas comerciales y de dominio público para explotar al máximo bases de datos o inclusive colecciones de información para cada uno de ellos.
En esta sección se muestra un ejemplo de cómo se pueden combinar esos modelos para diseñar sistemas que puedan mezclar todas estas tecnologías de manera que se logre el objetivo principal de la administración de información.
10.2 Acervo de documentos de tesis
10.2.1 Datos estructurados
Si se desea crear un acervo de tesis, se podría pensar en colocar un conjunto de directorios con todos los archivos identificados con alguna llave y probablemente en un manejador de bases de datos tener almacenados los metadatos que describen a los documentos.
Esto tiene varias caraterísticas:
- Es fácil de implementar
- No requiere un gran conocimiento de tecnologías más alla de las tradicionales de bd
- Sólo se está limitado a los metadatos
- Sólo se pueden recuperar documentos completos, no puedo recuperar sólo partes
- No puedo hacer búsquedas a partes específicas como "buscar la sección que tenga una figura que describa el ADN"
- No puedo hacer búsquedas a texto completo
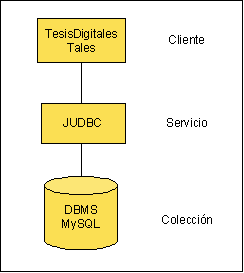
De manera que para solucionar los problemas anteriores podemos pensar en una solución de datos estructurados elaborando un modelo entidad-relación que contemple las distintas partes de los documentos de manera que tanto se puedan hacer búsquedas en distintas partes o secciones, como podamos recuperar partes específicas del documento ej, un capítulo.
 |
 |
10.2.2 Datos semiestructurados
Ahora ya se tiene un modelo más interesante pero aun con limitaciones, el tiempo de recuperacion puede ser muy prolongado si se desea por ejemplo reconstruir una tesis completa, estamos hablando de un promedio de hasta 3 seg.
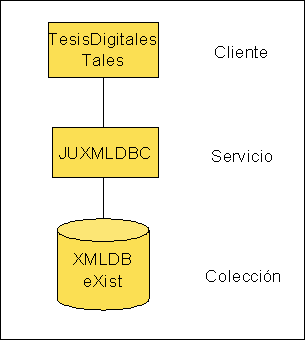
Surge la idea de utilizar entonces datos semiestructurados para modelar y administrar todos los documentos, en vista de que los documentos están formados por dichos datos.
De manera que construimos un DTD
<!ELEMENT thesis ( chapter | appendix )* > <!ELEMENT chapter (section)* > <!ELEMENT section (paragraph | figure | table | formula | code )* > <!ELEMENT appendix (paragraph | figure | table | formula | code )* > <!ELEMENT paragraph (#PCDATA) > <!ELEMENT figure (#PCDATA) > <!ELEMENT table (#PCDATA) > <!ELEMENT formula (#PCDATA) > <!ELEMENT code (#PCDATA) > <!ATTLIST thesis id CDATA #REQUIRED title CDATA #REQUIRED > <!ATTLIST chapter number CDATA #REQUIRED title CDATA #REQUIRED > <!ATTLIST section number CDATA #REQUIRED title CDATA #REQUIRED > <!ATTLIST appendix number CDATA #REQUIRED title CDATA #REQUIRED > <!ATTLIST paragraph title CDATA #REQUIRED > <!ATTLIST figure title CDATA #REQUIRED > <!ATTLIST table title CDATA #REQUIRED > <!ATTLIST formula title CDATA #REQUIRED > <!ATTLIST code title CDATA #REQUIRED > |
y elaboramos un ejemplo completo de una tesis en XML para verificar que se tiene contemplada toda la información.
<tesis> <indice> contenido indice </indice> <capitulo numero="1" titulo="introduccion"> <seccion numero="1.1"> contenido 1.1 </seccion> <seccion numero="1.2"> contenido 1.2 </seccion> </capitulo> <capitulo numero="2" titulo="desarrollo"> <seccion numero="2.1"> contenido 2.1 </seccion> </capitulo> <capitulo numero="3" titulo="conclusiones"> <seccion numero="3.1"> contenido 3.1 </seccion> <seccion numero="3.2"> contenido 3.2 </seccion> <seccion numero="3"> contenido 3.3 </seccion> </capitulo> </tesis> |
Para el almacenamiento y recuperación se emplea una base de datos xml (ej exist)
 |
Podemos aplicar consultas específicas hacia distintas partes del documento obteniendo excelentes tiempos de respuesta, ademas de que podemos usar hojas de estilo xsl para formatear las distintas partes para lograr un interfaz más amigable
Consulta |
Resultados |
Tiempo eXist (ms) |
Tiempo Xindice (ms) |
/thesis/chapter[contains(@title,'Intro')] |
139 |
900 |
30000 |
/thesis/chapter/section/figure[contains(@title,'UVA')] |
3 |
2800 |
8000 |
/thesis[@id='90'] |
1 |
340 |
8000 |
/thesis/chapter/section/table[contains(.,'UML')] |
10 |
3070 |
8000 |
/thesis/chapter[@number='2']/section |
744 |
1456 |
11000 |
/thesis/chapter[@number='2']/section[@number='2.2'] |
147 |
1427 |
9000 |
10.2.3 Datos no estructurados
Ahora se tiene un buen sistema que maneja todos los documentos de manera eficiente, pero ...Cómo hago una búsqueda a texto completo ?, tanto en el esquema relacional como en el XML una consulta de este tipo sería muy costosa ya que no están diseñados para tal fin. Así que podemos crear índices con una herramienta como Lucene para poder realizar consultas a todo o parte del contenido.
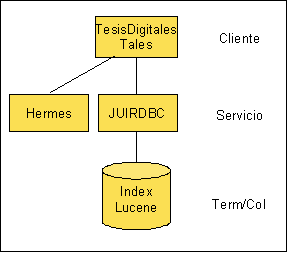 |
Nuevamente aplicando este índica y aplicando modelos de recuperación podemos saber qué documentos contienen ciertos términos y que tan relevantes son en cada uno; lo anterior con un excelente tiempo de respuesta.
Consulta |
Resultados |
TiempoEVH(ms) |
TiempoBEH(ms) |
TiempoEVL(ms) |
uva syrex rdu |
8 |
50 |
13 |
5 |
agente aglet nodo |
50 |
150 |
125 |
7 |
gis capa popocatepetl |
25 (8-BEH) |
80 |
60 |
42 |
10.2.4 Integración
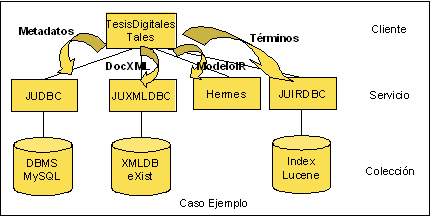
De manera que la integración de todas las tecnologías y de todos los datos estaría representada en la siguiente figura.
 |
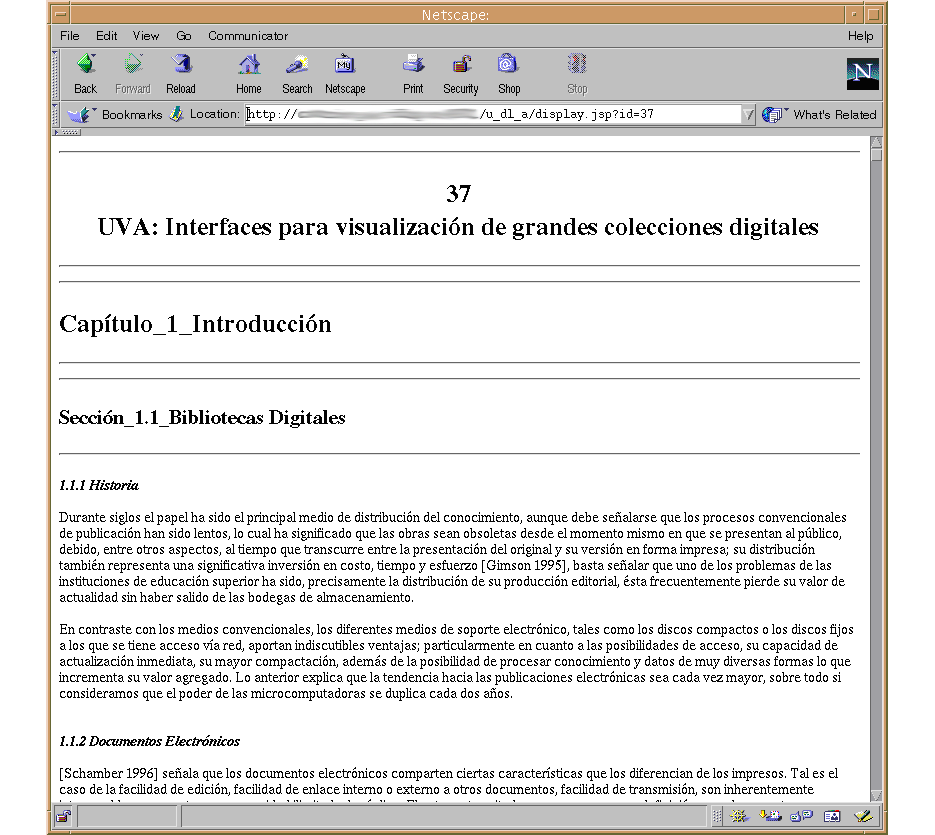
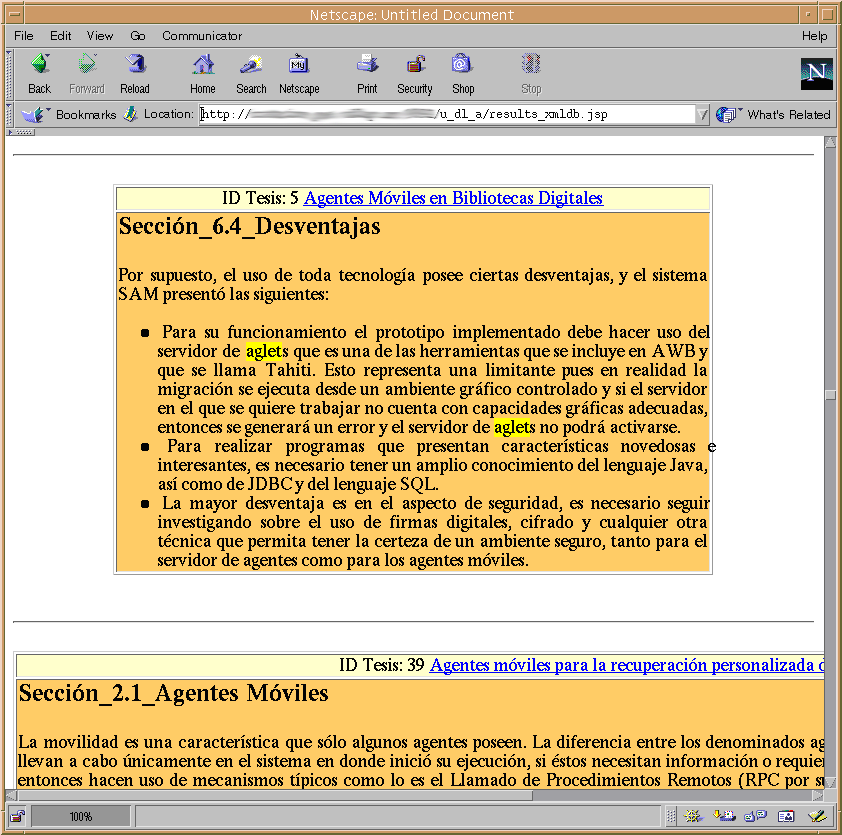
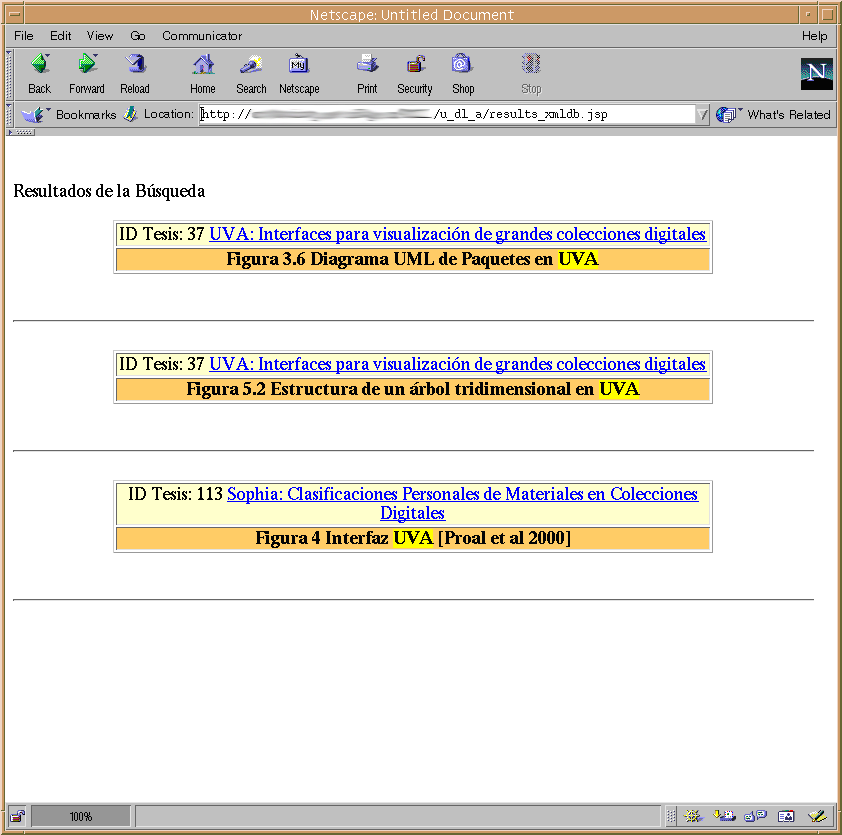
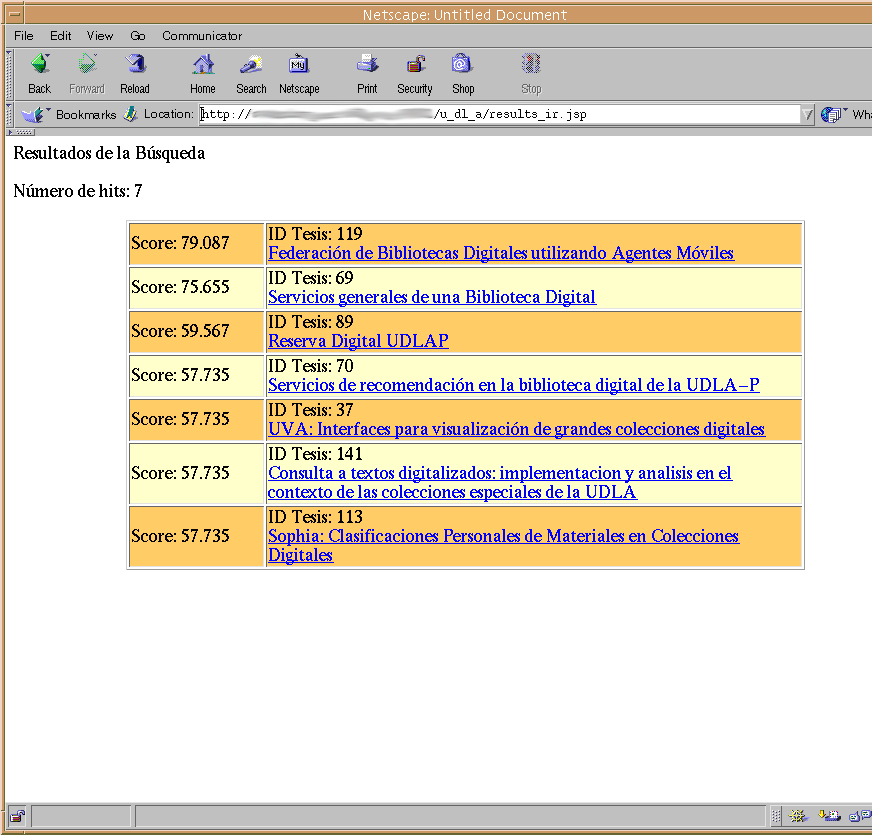
Las siguientes imágenes muestran la interfaz del sistema prototipo que incorpora lo mencionado anteriormente.
 |
 |
 |
 |
 |
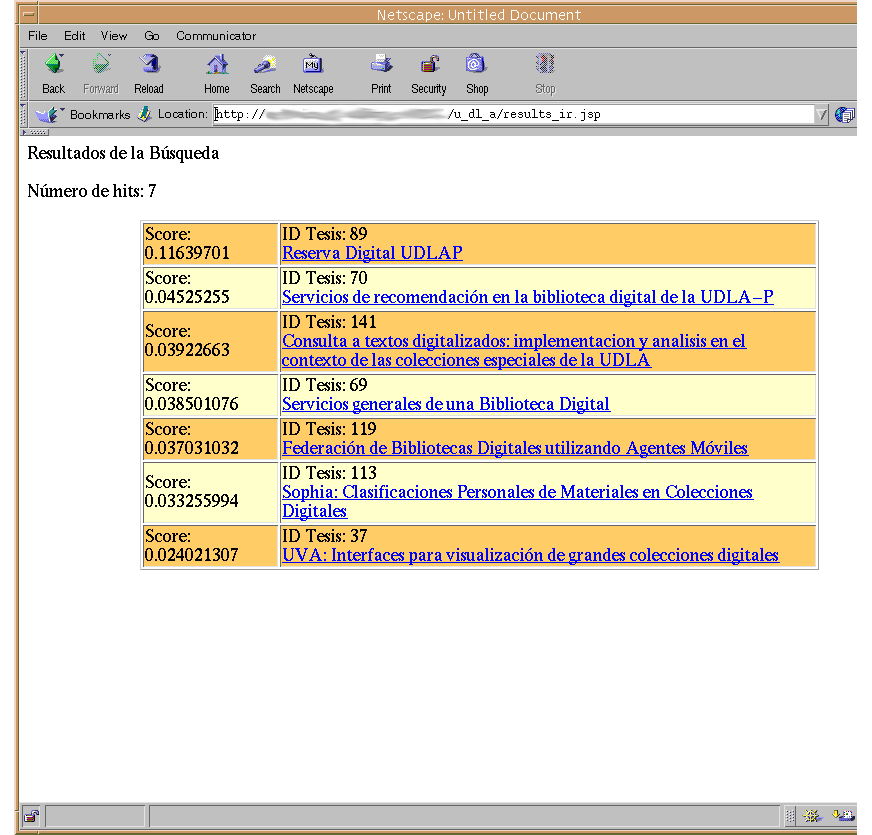 |
De esta manera se ha presentado un ejemplo de combinación de esquemas de los distintos tipos de datos (estructurados, semiestructurados y no estructurados). Para finalizar se muestra una figura de un esquema de una colección de documentos obtenidos a partir de hojas digitalizadas las cuales son analizadas con una herramienta OCR de manera que se pueden combinar los metadatos de las páginas con las palabras capturadas del OCR para tener un esquema mucho más rico de explotar.
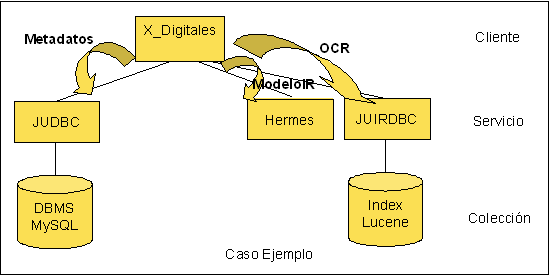 |