3. Developing the Model
3.1 Methodology
El data warehouse system data model se desarrolla aplicando un proceso de transformación de 8 pasos sobre el business data model. Estos 8 pasos son:
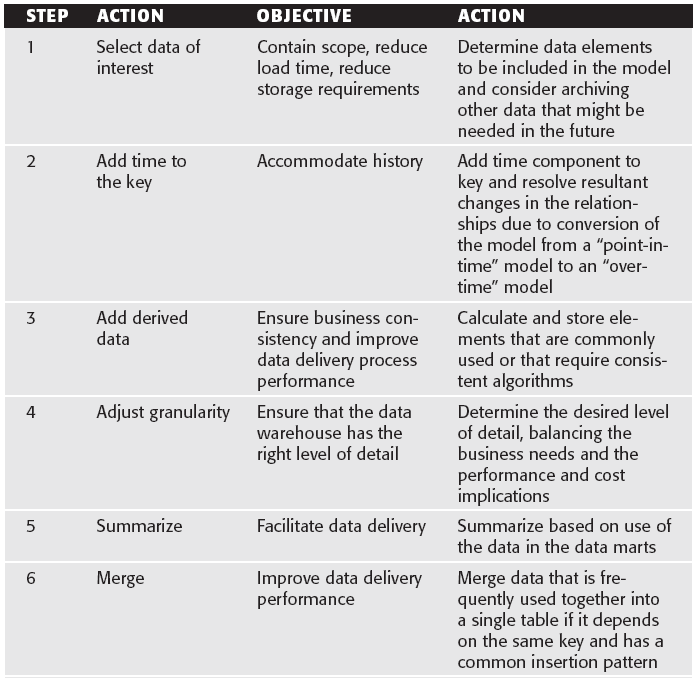
- Select the data of interest.
- Add time to the key.
- Add derived data.
- Determine granularity level.
- Summarize data.
- Merge entities.
- Create arrays.
- Segregate data.
Los 8 pasos pueden ser agrupados en 2 categorías:
- Los primeros cuatro, que tratan principalmente con los problemas de negocio. Se seleccionan los datos requeridos, se agregan fechas para acomodar el historial, datos derivados para crear consistencia y el nivel de granularidad es determinado para asegurar que los datos puedan satisfacer las necesidades.
- Los siguientes cuatro pasos, que principalmente son para fines de mejorar el rendimiento. Se crean sumarizaciones, entidades se mezclan para reducir los joins, se crean arreglos para facilitar la creación de data marts que necesitan análisis cruzado, los datos son segregados (separados) para fines de estabilidad (reducir el numero de tuplas) y uso (reducir la necesidad de hacer joins para satisfacer queries)
3.2 Step 1: Select the Data of Interest
Este es el primer paso, debido a que todas las decisiones concercientes al modelo del data warehouse consideran el propósito y objetivos del negocio. Ademas este paso define el alcance del modelo del data warehouse necesario para el proyecto.
3.2.1 Inputs
El business data model es solo una de las entradas para el paso 1. Otras entradas incluyen el documento del alcance del proyecto (project scope document), requerimientos de información, prototipos, reportes y consultas existentes, y el modelo de sistema o físico de los modelo que alimentarán el data warehouse.
3.2.2 Selection Process
La selección de los elementos de datos a ser incluido no es un proceso simple; puede haber una cantidad significativa de excesos de datos en el data warehouse si no se realiza con cuidado
Los datos en los sistemas operacionales basicamente caen en 3 grupos:
- Por ejemplo, fechas, cantidades de ventas, número de ventas, consisten de elementos que son definitivamente necesarios.
- Por ejemplo, fechas de actualización de registros, consisten de elementos que definitivamente no son necesarios.
- Por ejemplo, tiempo de venta, descuentos especiales, promociones, impuestos, consisten de elementos que pueden llegar a ser necesarios.
3.2.3 Use of Data Element for a Derived Field
Como regla general se recomienda mantener todo elemento usado para calcular algún dato derivado en el data warehouse. Esto por 2 razones: 1) Quizás haya que recalcularlos después, debido a alguna variación en el cálculo (ej, cambiar algun porcentaje), 2) Los usuarios podrían llegar a necesitar hacer un "drill down" hacia dichos valores
3.2.4 Classification of Data as Transactional or Reference
Dentro del data warehouse a veces en conveniente mantener actividades de las transacciones en cierto periodo de tiempo ( a veces años).
Es dificil decidir, si se tiene duda, lo mejor es mantener esa información en el datawarehouse.
Tres razones para hacerlo:
- La transacción puede ser purgada del sistema.
- Las transacciones ocurren después de tiempo de crear el dw.
- Integrar datos de transacciones es por lo general una tarea simple.
Muchas compañías usa una estrategia conocida como "triage", que se basa en almacenar aquellos datos de las transacciones en un almacenamiento lento o archivado offline, de manera que si los necesitan los pueden recuperar.
3.2.5 Source Data Structure
Revisar bien la fuente de los datos, muchas veces un dato aparece en una tabla pero en realidad pertenece a otra tabla de "referencia", siempre hay que buscar la tabla origen de todos los datos.
No incluir todas las columnas, la tentación debe ser evitada debido al tiempo de desarrollo, carga, almacenamiento e impacto en el rendimiento.
3.3 Step 2: Add Time to the Key
El business data model es un modelo “point-in-time” (en un punto del tiempo) . Esto es, el modelo representa el presente. El modelo en el data warehouse por otro lado representa un modelo "over-time" (a través del tiempo), que representa una empresa con una perspectiva histórica.
En un modelo entidad-relación E-R, la perspectiva histórica se logra para cada entidad de interés meramente agregando el tiempo/fecha a la llave de la entidad.
La inclusión de la historia tambien puede cambiar algunas relaciones de one-to-many a many-to-many.
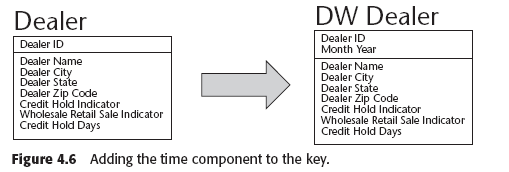 |
Capturar las fechas es un gran reto, sobre todo cuando es difícil asociarlas desde la fuente. Cuando un sistema no mantiene fechas de ciertas cosas importantes, entonces se utiliza la fecha en la que se hizo la extracción desde la fuente, hacia el data warehouse. Esto hace que la extracción muchas veces tenga que ser diaria o en ocasiones aún más recurrente.
Capturing Historical Data
Existen 5 estrategias que pueden escogerse:
- Generar una llave foránea dual, como ya se mencionó anteriormente.
- Generar una llave serial en la entidad padre de cada ocurrencia y almacenar el identificador y fecha como un atributo nollave dentro de la entidad. Este escenario reduce el número de atributos generados como llaves foráneas pero aún genera una nueva instancia del hijo cada vez que hay un cambio en la entidad padre.
- Programáticamente asegurar la integridad referencial, sin usar la del DBMS, y solo para el identificador. Este método requiere trabajo adicional de programación.
- Separar los datos en una entidad que contenga la historia y otra entidad contenga los datos actuales. Las relaciones solamente emanan de las tablas con los datos actuales y por lo tanto no incluyen componentes del tiempo. La integridad referencial para los datos históricos se realiza programáticamente copiando los registros de los datos actuales hacia el histórico
- Mantener la entidad base con los datos que nunca pueden cambiar y crear otra entidad con los datos que pueden cambiar en el tiempo. Esta técnica posibilita que la llave de la entidad base consista unicamente del identificador y dado que la otra entidad no tiene hijos, la fecha no cascadea.
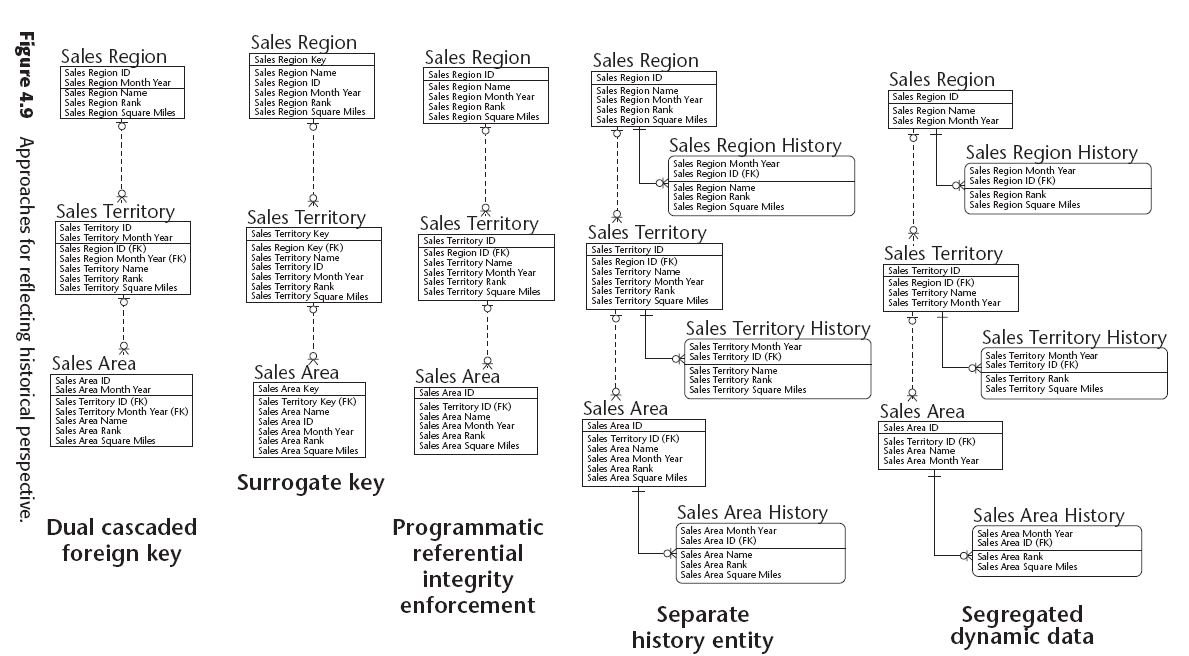 |
Capturing Historical Relationships
Las relaciones cambian tambien a lo largo del tiempo. El resultado de estos cambios es la creación de relaciones muchos-a-muchos.
3.4 Step 3: Add Derived Data
Datos derivados son el resultado de realizar una operación matemática en uno o más elementos. Los datos derivados son incorporados al data warehouse por 2 razones: asegurar consistencia y para mejorar el rendimiento.
Es extremadamente importante que todo el mundo entienda que esta incluido y excluido en el cálculo.
Otro ejemplo de un campo derivado es la fecha misma.
El número de días en el mes es otro campo que puede tener otro significado y que muchas veces es utilizado en cálculos de divisiones.
- El primer día es excluido?
- El último día es excluido ?
- Los sábados son excluídos ?
- Los domingos son excluídos ?
- Los días festivos son excluídos ? cuáles son ?
- Los días de paro con excluídos ? cuáles son ?
Crear un campo derivado no ahorra espacio, ya que cada resultado es almacenado. Mejora el rendimiento de lectura a expensas de alentar el tiempo de cargado.
3.5 Step 4: Determine Granularity Level
El nivel de granularidad es significante desde el punto de vista de negocio, técnico y de proyecto.
Desde la perspectiva de negocio, dicta el potencial y flexibilidad del data warehouse, sin importar las funciones desplegadas. Sin un cambio subsecuente en la granularidad, el data warehouse no podrá contestar consultar de un nivel de detalle diferente al adoptado.
Desde una perspectiva técnica, es una de las cuestiones más determinantes del tamaño del data warehouse lo cual impacta al costo y rendimiento.
Desde la perspectiva del proyecto, la granularidad afecta la cantidad de trabajo que el equipo necesitará para crear el data warehouse, más o menos atributos, más o menos relaciones.
Existen diversos factores que determinan el nivel de granularidad de los datos en el warehouse:
- Current business need. Al menos, el nivel de granularidad debe poder satisfacer las consultas de cada interrogante actual. Agregar demasiado nivel de granularidad (innecesario) solo aumenta los costos sin ninguna razón.
- Anticipated business need. Sin embargo, si el proceso de la entrevista revela la necesidad de ciertos datos en el futuros, éstos deben ser "considerados" en el diseño de data warehouse.
- Extended business need. Considerar niveles de granularidad típicos para cierta industria, por ejemplo, en los negocios de venta al menudeo, se mantienen datos a nivel transacción para diversos análisis.
- Data mining need. Por ejemplo, si el negocio necesita saber qué productos vender con otros, análisis de transacciones individuales es necesario.
- Derived data need. Datos derivados que usan otros datos en el cálculo.
- Operational system granularity. Otro factor es el nivel de detalle disponible en el sistema operacional, sistemas que alimentan al data warehouse.
- Data acquisition performance. El performance al cargar los datos se ve directamente afectado por la granularidad.
- Storage cost. Si un distribuidor tiene 1,000 tiendas y cada una tiene 1,500 ventas al dia, cada una con 10 productos, el nivel de detalle a cada transacción significarían 15,000,000 de tuplas por día.
- Administration. La administración del data warehouse aumenta o disminuye también.
3.6 TIP despúes del 4o paso
Una vez terminados los primeros 4 pasos, se puede proceder a explotar dichos datos (ej. creando el primer data mart) para ir cubriendo las necesidades del negocio. Al mismo tiempo se refinan aspectos de rendimiento siguiendo los siguientes 4 pasos.
3.7 Step 5: Summarize Data
El proceso de resumir/sumar datos no ahorra espacio, porque inclusive los datos empleados se mantienen; sin embargo mejora el tiempo de respuesta al momento de la entrega de información.
El criterio más común para sumar es por "rebanadas de tiempo".
Existen 5 tipos de resúmenes: :
- simple cumulations
- rolling summaries
- simple direct files
- continuous files
- vertical summaries.
Simple cumulations y rolling summaries aplican a datos que pertenecen a cierto periodo de tiempo.
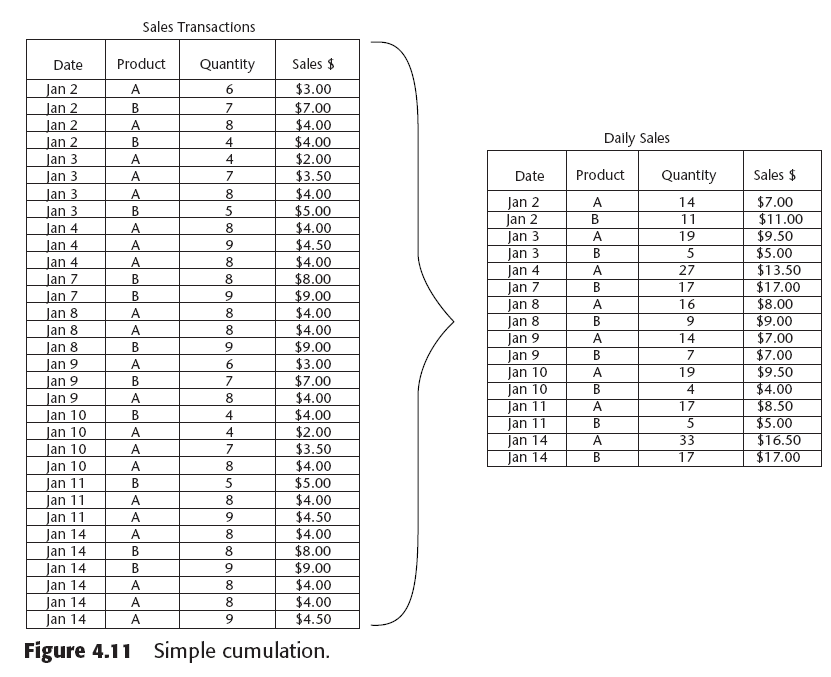 |
Un rolling summary provee información de ventas para un periodo de tiempo consistente.
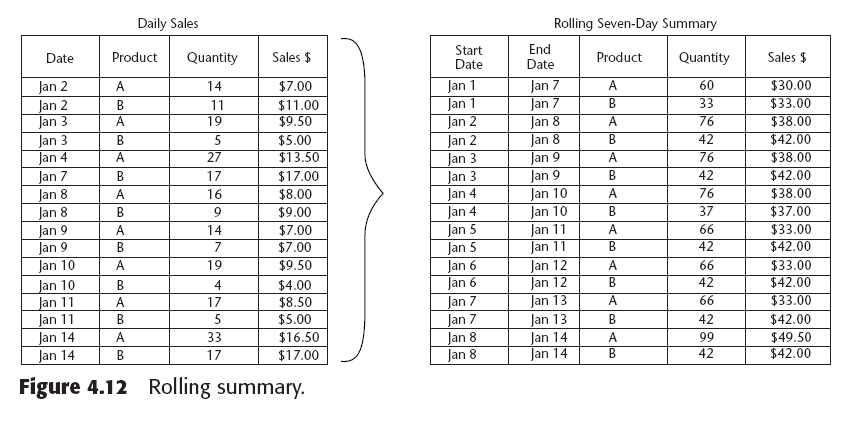 |
El direct summary y continuous summary aplican a snapshot de datos o datos periódicos o pertenecientes a un punto en el tiempo.
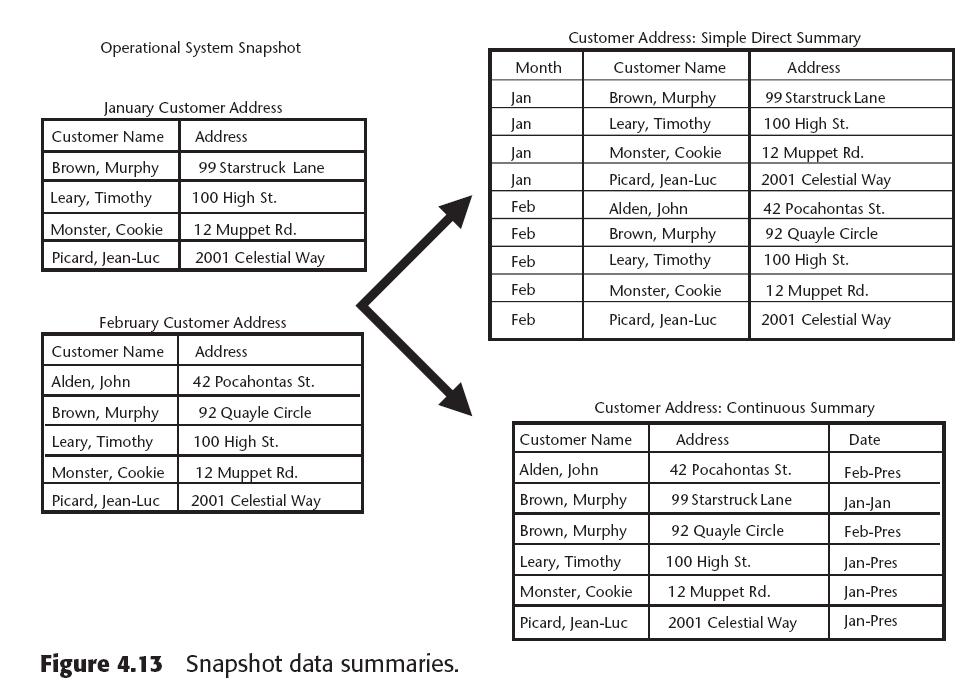 |
Vertical Summary
Aplica a ambos, puntos en el tiempo y periodos de tiempo.
3.8 Step 6: Merge Entities
Mezclar entidades es combinar dos o más entidades en una sola.
Es una forma de denormalización de datos. Exige la creación de dimensiones que serán usadas en los data marts.
El criterio para decidir qué entidades mezclar: las entidades deben tener una llave común, los datos de dichas entidades de usan juntos a menud y el patrón de inserción es similar.
3.9 Step 7: Create Arrays
Raramente utilizado, pero cuando es necesario puede mejorar considerablemente la población de data marts.
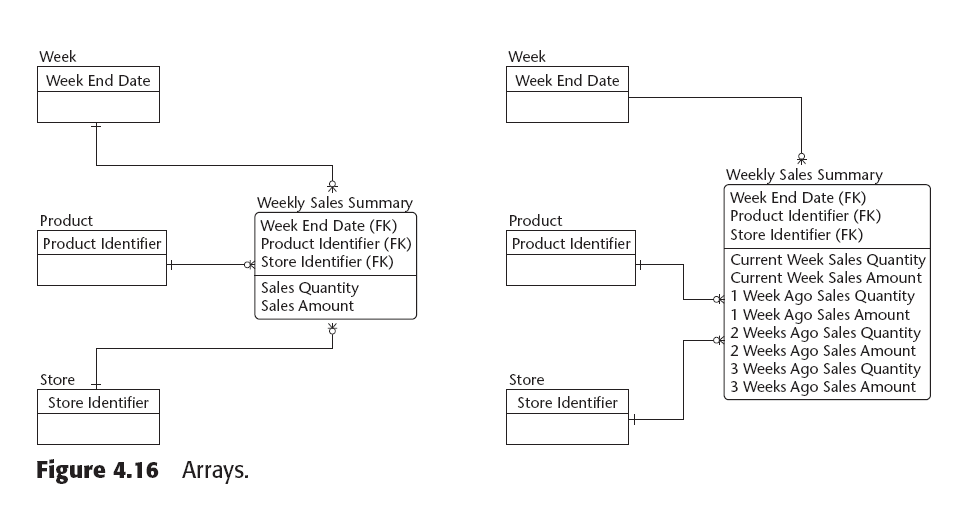 |
3.10 Step 8: Segregate Data
Separar datos basándose en estabilidad y uso.
Si se lleva al extremo, una entidad separada debería crearse por cada pieza de datos.
3.11 Resumen
|