4. Modelado multidimensional
4.1 Antecedentes
Inmon propone un modelado a partir del modelo de negocio, pero Kimball (et al) proponen usar un modelo multidimensional, basado en "facts" y "dimensions".
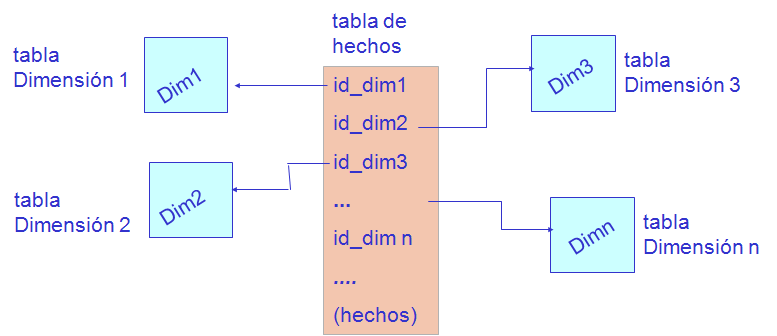
Modelado multidimensional: en un esquema multidimensional se representa una actividad que es objeto de análisis (hecho) y las dimensiones que caracterizan la actividad (dimensiones).
La información relevante sobre el hecho (actividad) se representa por un conjunto de indicadores (medidas o atributos de hecho).
La información descriptiva de cada dimensión se representa por un conjunto de atributos (atributos de dimensión).
El modelado multidimensional se puede aplicar utilizando distintos modelos de datos (conceptuales o lógicos).
La representación gráfica del esquema multidimensional dependerá del modelo de datos utilizado (relacional, ER, UML, OO, ...).
El desarrollo de la tecnología de data warehouses se ha caracterizado por:
- un temprano desarrollo industrial provocado por las demandas de los usuarios.
- el uso de metodologías de diseño centradas principalmente en los niveles lógico e interno. (la atención se ha centrado en mejorar la eficiencia en la ejecución de consultas)
 |
4.2 Pasos en el diseño del DW (modelado multidimensional)
-
Paso 1. Elegir un “proceso” de la organización para modelar.
-
Paso 2. Decidir el gránulo (nivel de detalle) de representación del proceso.
-
Paso 3. Identificar las dimensiones que caracterizan el proceso.
-
Paso 4. Decidir la información a almacenar sobre el proceso.
4.2.1 Paso 1 Elegir un “proceso” de la organización para modelar.
Proceso: actividad de la organización soportada por un OLTP del cual se puede extraer información con el propósito de construir el almacén de datos.
- Pedidos (de clientes)
- Compras (a suministradores)
- Facturación
- Envíos
- Ventas
- Inventario
- etc
Ejemplo: Cadena de supermercados.
Cadena de supermercados con 300 almacenes en la que se expenden unos 30.000 productos distintos.
Actividad: Ventas.
La actividad a modelar son las ventas de productos en los almacenes de la cadena.
4.2.2 Paso 2 Decidir el gránulo (nivel de detalle) de representación.
Gránulo: es el nivel de detalle al que se desea almacenar información sobre la actividad a modelar.
- El gránulo define el nivel atómico de datos en el almacén de datos.
- El gránulo determina el significado de las tuplas de la tabla de hechos.
- El gránulo determina las dimensiones básicas del esquema
- transacción en el OLTP
- información diaria
- información semanal
- información mensual. ....
Ejemplo: Cadena de supermercados.
- Gránulo: “se desea almacenar información sobre las ventas diarias de cada producto en cada almacén de la cadena”.
- Gránulo:
- define el significado de las tuplas de la tabla de hechos.
- determina las dimensiones básicas del esquema.
 |
- Gránulo inferior: no se almacena información a nivel de línea de ticket porque no se puede identificar siempre al cliente de la venta lo que permitiría hacer análisis del comportamiento (hábitos de compra) del cliente.
- Gránulo superior: no se almacena información a nivel semanal o mensual porque se perderían opciones de análisis interesantes: ventas en días previos a vacaciones, ventas en fin de semana, ventas en fin de mes, ....
Nota: En un DW se almacena información a un nivel de detalle (gránulo) fino no porque se vaya a interrogar el almacén a ese nivel sino porque ello permite clasificar y estudiar (analizar) la información desde muchos puntos de vista.
4.2.3 Paso 3 Identificar las dimensiones que caracterizan el proceso.
-
Dimensiones: dimensiones que caracterizan la actividad al nivel de detalle (gránulo) que se ha elegido.
- Tiempo (dimensión temporal: ¿cuándo se produce la actividad?)
- Producto (dimensión ¿cuál es el objeto de la actividad?)
- Almacén (dimensión geográfica: ¿dónde se produce la actividad?)
- Cliente (dimensión ¿quién es el destinatario de la actividad?)
-
De cada dimensión se debe decidir los atributos (propiedades) relevantes para el análisis de la actividad.
-
Entre los atributos de una dimensión existen jerarquías naturales que deben ser identificadas (día-mes-año)
 |
Ejemplo: Cadena de supermercados.
 |
 |
Nota: En las aplicaciones reales el número de dimensiones suele variar entre 3 y 15 dimensiones.
Dimensión Tiempo:
- dimensión presente en todo AD porque el AD contiene información histórica sobre la organización.
- aunque el lenguaje SQL ofrece funciones de tipo DATE, una dimensión Tiempo permite representar otros atributos temporales no calculables en SQL.
- se puede calcular de antemano
- atributos frecuentes:
- nro. de día, nro. de semana, nro. de año: valores absolutos del calendario juliano que permiten hacer ciertos cálculos aritméticos.
- día de la semana (lunes, martes, miércoles,...): permite hacer análisis sobre días de la semana concretos (ej. ventas en sábado, ventas en lunes,..).
- día del mes (1..31): permite hacer comparaciones sobre el mismo día en meses distintos (ventas el 1º de mes).
- marca de fin de mes, marca de fin de semana : permite hacer comparaciones sobre el último día del mes o días de fin de semana en distintos meses.
- trimestre del año (1..4): permite hacer análisis sobre un trimestre concreto en distintos años.
- marca de día festivo: permite hacer análisis sobre los días contiguos a un día festivo.
- estación (primavera, verano..)
- evento especial: permite marcar días de eventos especiales (final de futbol, elecciones...)
- jerarquía natural: día - mes - trimestre -año
Dimensión Producto:
- la dimensión Producto se define a partir del fichero maestro de productos del sistema OLTP.
- las actualizaciones del fichero maestro de productos deben reflejarse en la dimensión Producto (¿cómo?).
- la dimensión Producto debe contener el mayor número posible de atributos descriptivos que permitan un análisis flexible. Un número frecuente es de 50 atributos.
- atributos frecuentes: identificador (código estándar), descripción, tamaño del envase, marca, categoría, departamento, tipo de envase, producto dietético, peso, unidades de peso, unidades por envase, fórmula, ...
- jerarquías: producto-categoría-departamento
Dimensión Establecimiento (store) :
- la dimensión Almacén representa la información geográfica básica.
- esta dimensión suele ser creada explícitamente recopilando información externa que sólo tiene sentido en el A.D y que no la tiene en un OLTP (número de habitantes de la ciudad del establecimiento, caracterización del tipo de población del distrito, ...)
- atributos frecuentes: identificador (código interno), nombre, dirección, distrito, región, ciudad, país, director, teléfono, fax, tipo de almacén, superficie, fecha de apertura, fecha de la última remodelación, superficie para congelados, superficie para productos frescos, datos de la población del distrito, zona de ventas, ...
- jerarquías:
- establecimiento - distrito - ciudad - región - país (jerarquía geográfica)
- establecimiento - zona_ventas - región_ventas (jerarquía de ventas)
Dimensiones
 |
StarSchema
 |
4.2.4 Paso 4 Decidir la información a almacenar sobre el proceso.
Hechos: información (sobre la actividad) que se desea almacenar en cada tupla de la tabla de hechos y que será el objeto del análisis.
- Precio
- Unidades
- Importe ....
Nota: algunos datos que en el OLTP coincidirían con valores de atributos de dimensiones, en el almacén de datos pueden representar hechos. (Ejemplo: el precio de venta de un producto).
Ejemplo: Cadena de supermercados.
Gránulo: “se desea almacenar información sobre las ventas diarias de cada producto en cada establecimiento de la cadena”.
- importe total de las ventas del producto en el día
- número total de unidades vendidas del producto en el día
- número total de clientes distintos que han comprado el producto en el día.
StarSchema
 |
4.3 Otras orientaciones de diseño
4.3.1 Uso de claves sin significado.
- en un almacén de datos debe evitarse el uso de las claves del sistema operacional.
- las claves de las dimensiones deben ser generadas artificialmente: claves de tipo entero (4 bytes) son suficiente para dimensiones de cualquier tamaño (232 valores distintos).
- la dimensión TIEMPO debe tener también una clave artificial.
4.3.2 Evitar normalizar.
Si se define una tabla de dimensión para cada dimensión identificada en el análisis, es frecuente que entre el conjunto de atributos de la tabla aparezcan dependencias funcionales que hacen que la tabla no esté en 3NF.
Evitar normalizar:
- el ahorro de espacio no es significativo
- se multiplican los JOIN durante las consultas.
4.3.3 Siempre introducir la dimensión Tiempo.
Necesario siempre incluir el histórico.
4.3.4 Dimensiones “que cambian”.
Se considera relevante el caso en que, en el mundo real, para un valor de una dimensión, cambia el valor de un atributo que es significativo para el análisis sin cambiar el valor de su clave.
Ejemplo: En un A.D existe la dimensión CLIENTE. En la tabla correspondiente un registro representa la información sobre el cliente “María García” cuyo estado civil cambia el 15-01-1994 de soltera a casada. El estado civil del cliente es utilizado con frecuencia en el análisis de la información.
Existen tres estrategias para el tratamiento de los cambios en las dimensiones:
- Tipo 1: Realizar la modificación.
- Tipo 2: Crear un nuevo registro.
- Tipo 3: Crear un nuevo atributo.
4.3.5 Definición de agregados.
¡En un almacén de datos es usual consultar información agregada!
El almacenamiento de datos agregados por distintos criterios de agregación en la tabla de hechos mejora la eficiencia del AD.
Estrategias de almacenamiento de datos agregados:
- Estrategia 1: definir nuevas tablas de hechos (resp. de dimensiones) para almacenar la información agregada (resp. la descripción de los niveles de agregación).
- Estrategia 2: insertar en la tabla de hechos (resp. dimensiones) tuplas que representan la información agregada (resp. los niveles de agregación).
4.4 Star schemas, SnowFlakes y Constellations
 |
 |
 |
 |
El snowflake, facilita la actualización de información, pero es preferible evitarlo. No ahorra espacio y solo introduce mayor complejidad al modelo.
 |
 |
 |