8. External data, Unstructured data y el Data warehouse
8.1 External data
8.1.1 Antecedentes
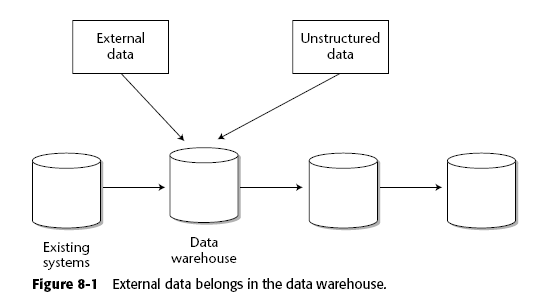
Normalmente la mayor parte de la información contenida en el datawarehouse proviene de fuentes internas a la compañía.
Pero también pueden existir fuentes externas que se agregan al datawarehouse para poder sustentar muchas cosas, tan simple como el cambio de moneda en ese instante de tiempo, hasta cosas más complicadas como "que tanto afectó la caída del mercado mobiliario de USA dentro del mercado mexicano".
 |
8.1.2 Tipos de datos externos
Existen 2 tipos básicos de datos externos:
- Registros de datos externos recolectados por alguna fuente (como una farmacia, supermercado, etc).
- Datos externos de reportes aleatorios, artículos y otras fuentes.
Algunas fuentes típicas de datos externos útiles e interesantes incluyen:
- Wall Street Journal
- Business Week
- Forbes
- Fortune
- Periodicos de cada industria
- Reportes de tecnología
- Reportes generados por consultores específicamente para la corporación
- Reportes de análisis competitivo
- Comparación de mercados y reportes de análisis
- Análisis de ventas y reportes comparativos
- Anuncios de nuevos productos
8.1.3 Problemas con datos externos en el dw
Existen 2 problemas principales con el manejo de datos externos:
- Frecuencia de la disponibilidad. A diferencia de los internos, muchos externos tienen distinta disponibilidad, en el mejor de los casos tienen cierta periodicidad, pero en otros hay que estar "alertas" acerca de dichos datos.
- Son datos totalmente no-disciplinados. Reformatear, reestructurar, revisar granularidad, son de las tareas que hay que realizar cuando agregamos algo externo, de manera que sea coherente con lo que se genera internamente.
- Los datos externos son impredecibles. Pueden venir de cualquier fuente, en cualquier momento.
 |
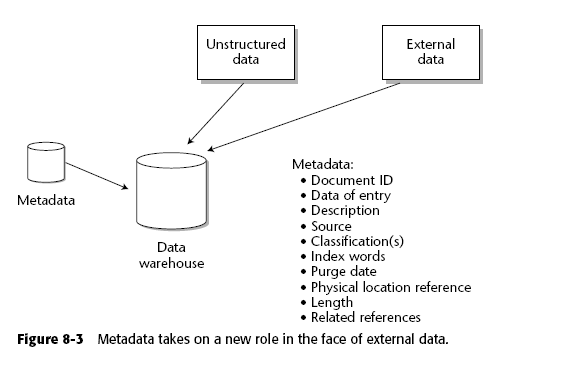
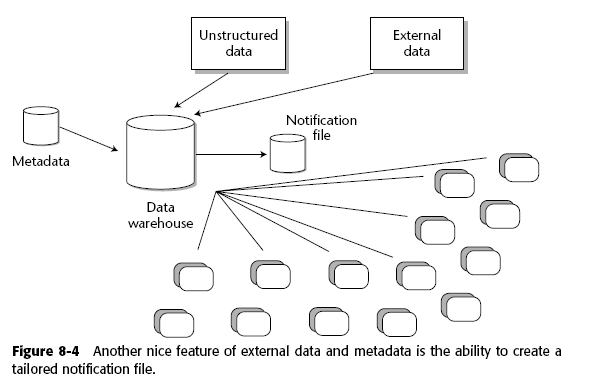
8.1.4 Metadata de los datos externos
Es importante agregar metadatos a los datos externos, ya que es la manera de poderlos controlar y manejar más fácilmente por el administrador. Por ejemplo, para saber si un dato es "fiel" puede checarse la fuente y la fecha, si es muy viejo quizás ese dato es obsoleto, de igual manera si la fuente no es confiable se deshecha dicha información.
 |
 |
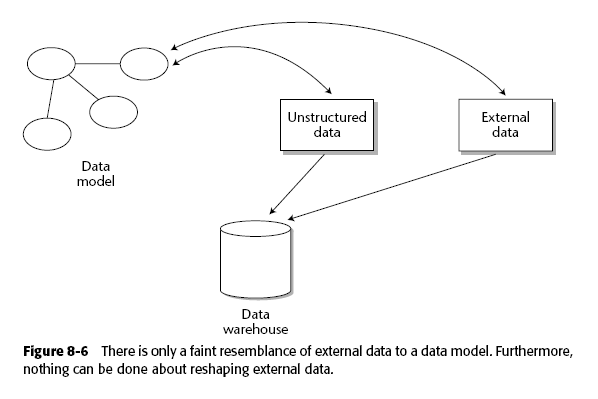
8.1.5 Modelado y datos externos
En el modelado del DW debe incluirse desde luego los metadatos de los datos externos, desambigüar algunos términos para evitar confusiones y eso es todo. En realidad hay poco de relación entre los datos externos y el modelo, ya que, como se mencionará después, inclusive tendrán estructuras diferentes (datos no estructurados)
 |
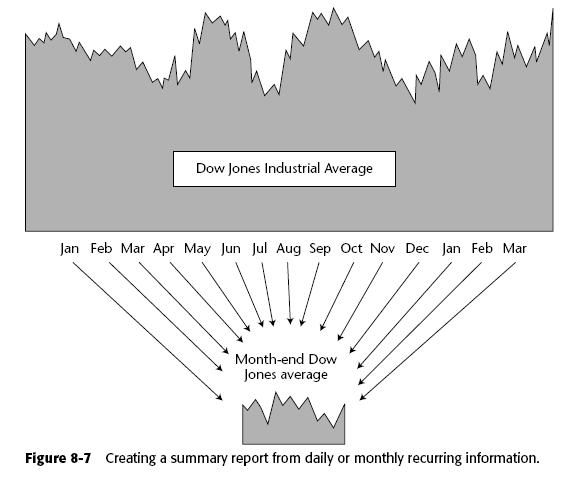
8.1.6 Reportes secundarios
En ocasiones es útil sumar o numerizar varios datos externos para simplificar su manejo. Por ejemplo, el cambio de monera o el precio del petróleo se generan diariamente, pero quizás nos interese más bien el promedio al mes, o si algo se genera por meses entonces el promedio al año.
 |
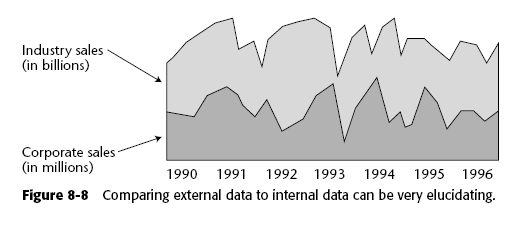
8.1.7 Comparando datos internos y externos
La mayor utilidad de tener datos externos resulta cuando podemos comparar tendencias internas contra lo externos. En el ejemplo se muestra cómo la tendencia de ventas de una compañía de 'X' industria se ajusta a la tendencia general de dicha industria 'X' a nivel nacional, de manera que esos descensos de 1993 no solo le pasaron a la compañía, sino a la industria en general.
 |
8.2 Unstructured data
8.2.1 Antecedentes
Los datawarehouses en su mayoría almacenan transacciones (compras, ventas, inventarios) los cuales son datos estructurados que tiene un tipo y longitud definida. Pero también existe la necesidad de agregar en un dw datos que no tienen estructura definida, por ejemplo:
- Emails
- Hojas de cálculo
- Archivos de texto
- Documentos
- Archivos Portable Document Format (.PDF)
- Presentaciones Microsoft PowerPoint (.PPT)
 |
 |
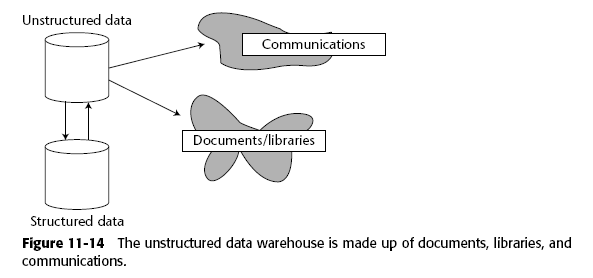
8.2.2 Tipos de datos estructurados
 |
8.2.3 Integrando datos estructurados y no estructurados
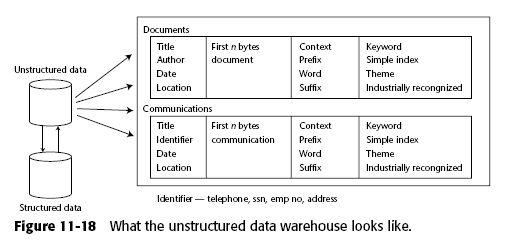
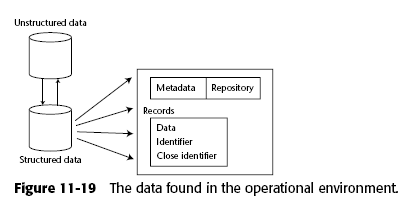
Supongamos el caso de un CRM (Customer Relationship Management), donde por un lado tenemos datos estructurados (edad, nombre, genero) y por otro tenemos datos no estructurados (emails, entrevistas, llamadas telefónicas). Los datos se agregan al dw con las técnica ya mencionadas, los datos estructurados como parte del modelo y los no estructurados de cierta manera como datos externos.
 |
 |
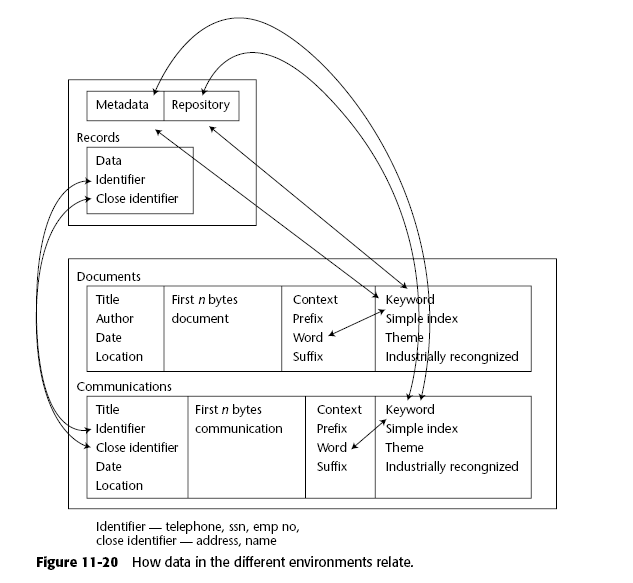 |
El problema es que ahora necesitan "ligarse" porque se puede dar el caso de que en un email yo hable de un producto o una persona que no aparece en los metadados y es evidente que es útil poder establecer esa relación.
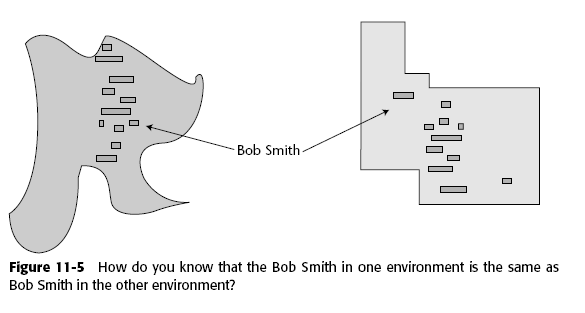 |
La clave para establecer la relación es simplemente el texto. Hay que analizar el texto contenido en los datos no estructurados y tratar de hacer un "match" contra aquellos datos que si son estructurados.
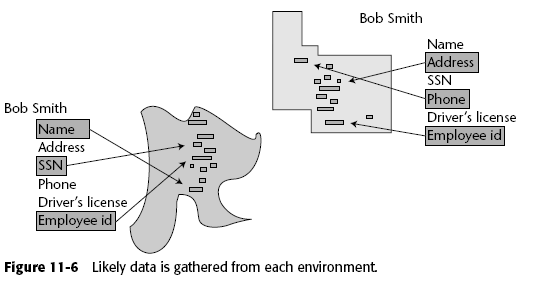 |
El problema es que simplemente analizar texto puede provocar varios problemas:
- Misspelling—Qué pasa si 2 palabras son la misma pero se han escrito diferente ? ej. Chernobyl y Chernobile?
- Context—Una palabra puede tener contextos diferentes, ej. el Sr. Vaca y el producto Vaca.
- Same name —Jesús Hernández por ejemplo, es el nombre más repetido en México.
- Nicknames—Andrés Manuel López Obrador, AMLO, Sr. López, Andrés Manuel.
- Diminutives —31 Oriente, 31 Ote, NY, New York
- Incomplete names —Fox y Vicente Fox
- Word stems —Computación y computadora
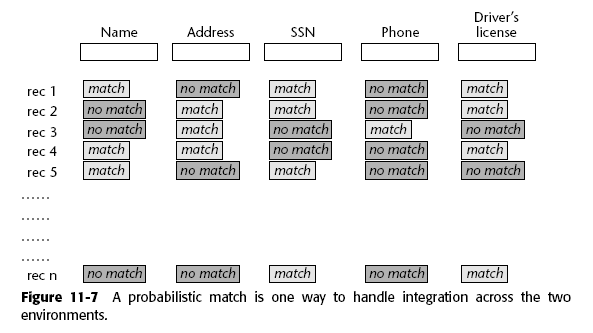
Comparación probabilística
Una solución es aplicar limpieza de las palabras y realizar una comparación probabilística para determinar los matches entre ambos ambientes. Aca entran los algoritmos de recuperación de información.
 |
Comparación basada en Temas
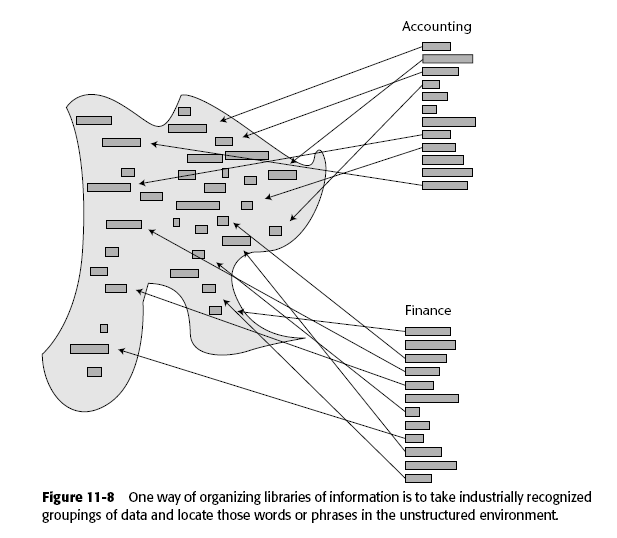
Otra solución es utilizar temas (Theme) con vocabulario controlado de cada industria para tratar de establecer una relación.
Ejemplo:
Accounting
|
Finance
|
 |
8.2.4 Visualización de datos
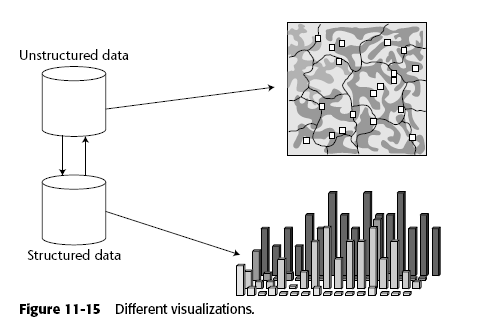
Los datos estructurados suelen representarse con gráficas (barras, pie, histograma).
Mientras que los datos no estructurados suelen representarse con un SOM (Self-Organizing Map) una especie de mapa topográfico que agrupa en clusters aquellos documentos de "temas" similares.
 |